上一篇我们提到,Flink是一个准确、实时、高吞吐的流式数据处理系统,那么它是如何实现的呢?本篇博客描述Blink的原理和架构。
需要解决的问题
批和流的区别
Flink官网的这张图,清晰地解释了批和流的区别。
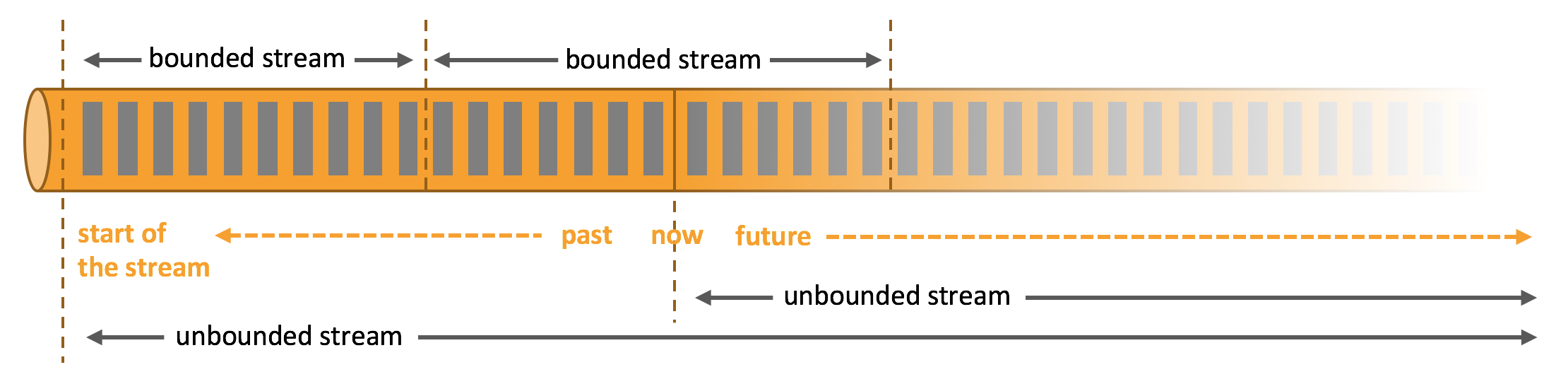
批数据是在时间上有界的数据。批处理场景,需要处理的数据量是确定的。
流数据是在时间上无界的数据。相对于批数据,流数据增加了一个新的时间维度,数据处理的难度也相应提升。
流处理和批处理的共性问题
流处理和批处理,需要处理的对象都是大数据,需要解决大数据处理的共性问题。
CAP限制
CAP定理是大数据处理的基础理论,对一个分布式计算系统,C(Consistency 一致性)、A(Availability 可用性)、P(Partition tolerance 分区容忍性)不能同时满足。
因为大数据处理是在分布式环境下执行的,所以P是默认要满足的。那么C和A之间,就只能满足一个,需要做出权衡取舍。
对于批处理系统,追求的是C,保证结果的正确性,牺牲了A,因为批处理对延时不敏感,几分钟甚至几小时之内获得计算结果都可以。
对于流处理系统,问题就比较棘手,首先要保证C,用户对数据处理的基本需求,是要获得正确的结果。但是A也不能牺牲,因为流式数据处理天然有实时性的需求,较高的数据延时会严重影响用户体验。受CAP定理的约束,C和A是不可兼得的,于是在流式处理系统中,问题被定义成:在保证准确性的前提下,尽可能地追求实时性。
任务调度
分布式处理系统,通常采用master-slave架构进行任务调度,包含一个master节点和多个slave节点。master节点负责分配任务,并管理任务的执行信息,slave节点负责执行具体的任务。如何让数据处理任务高效地执行,是每个分布式处理系统都需要考虑的问题。
资源管理
分布式集群中,通常同时运行着许多任务。如何高效地利用集群中的CPU、内存、带宽,保证任务能够获取到所需的资源,需要对资源进行合理地抽象和管理。
流处理的特有问题
相对于批处理,流处理需要处理的数据,增加一个新的维度 —— 时间,流处理系统需要考虑时间维度带来的额外复杂性。
正确性语义
对于批处理来说,将输入数据批量读取,处理之后进行合并,就可以得到正确结果。但是对于流数据处理,问题变得更加复杂。
流处理系统源源不断地读取输入,需要源源不断地输出计算结果,并保证输出的结果总是正确的,哪怕在输入数据乱序或者迟到的情况下,也要支持输出正确的结果。
出错处理
批出理的出错处理相对简单,在完整的数据集上重跑出错的任务即可。流数据的出错处理则不能这样做,因为输入数据是源源不断的,不存在"完整的数据集"。
对流数据处理系统来说,要进行容错,必然要存储中间状态,出错之后从存储的状态中恢复,并重放后续的数据。对于中间状态的管理和恢复,必须做得足够轻量,以保证系统整体的实时性和吞吐量。
流量控制
流处理任务中的每一个节点,处理数据的速度都是有上限的。当数据的流量在某些时刻超出了节点的上限时,流处理系统需要启动流量控制机制,防止一个节点的压力形成雪崩效应,影响到整个系统的数据处理。
流处理系统的目标
优秀的流处理系统,需要解决好大数据处理的共性问题,以及流处理的特有问题,满足正确性、实时性、高吞吐、灵活性的目标。下面我们来看一看Flink的设计细节。
Flink解决方案
整体架构
Flink整体架构如图所示:

Flink系统由Flink Program、JobManager、TaskManager三个部分组成。
Flink Program 加载用户提交的任务代码,解析并生成任务执行拓扑图,并将拓扑图提交给JobManager。
JobManager基于任务执行拓扑图,生成相应的物理执行计划,将执行计划发送给TaskManager执行。除此之外,JobManager还负责协调checkpoint的生成,不断地从TaskManager收集Operator的状态,并周期性生成checkpoint,以便在系统出错时从checkpoint恢复之前的状态。
TaskManager负责管理任务执行所需的资源,执行具体的任务,并将任务产出的数据流传入给下一个任务。
Flink Program、JobManager、TaskManager 之间,使用Akka框架(Actor System)进行通信, 通过发送消息驱动任务的推进。
资源管理
在流式数据处理的场景,输入数据是连续的,每一条数据大小接近,并且处理完就可以丢弃,无需落盘。JVM的内存管理机制,存在着对象存储密度低,内存利用率不高,大内存时GC停顿较长,影响系统吞吐量等问题,在流处理场景下效率不高,于是Flink抽象了一套自己的内存管理机制。
TaskManager是Flink任务执行的容器,提供了内存管理、IO管理、网络管理功能。
每个TaskManger上运行一个jvm进程。每个TaskSlot运行一个线程,瓜分Task Manager的内存。

为了提高资源的利用率,Flink允许同一个任务的多个子任务,在同一个TaskSlot中执行。通过Resource Group 机制,Flink会尽量将多个子任务放到一个slot中执行,用户也可以使用自定义的资源共享逻辑。
MemoryManager
Flink通过MemoryManager管理内存, 以MemorySegment为单位。默认情况下,MemorySegment可以看做是32kb大的内存块抽象,可以操作堆内和对外内存,Flink通过引用计数来释放MemorySegment。
IOMananger
Flink通过IOManger管理磁盘IO,提供了同步和异步两种写模式,底层通过异步的方式进行读写。
NetworkManager
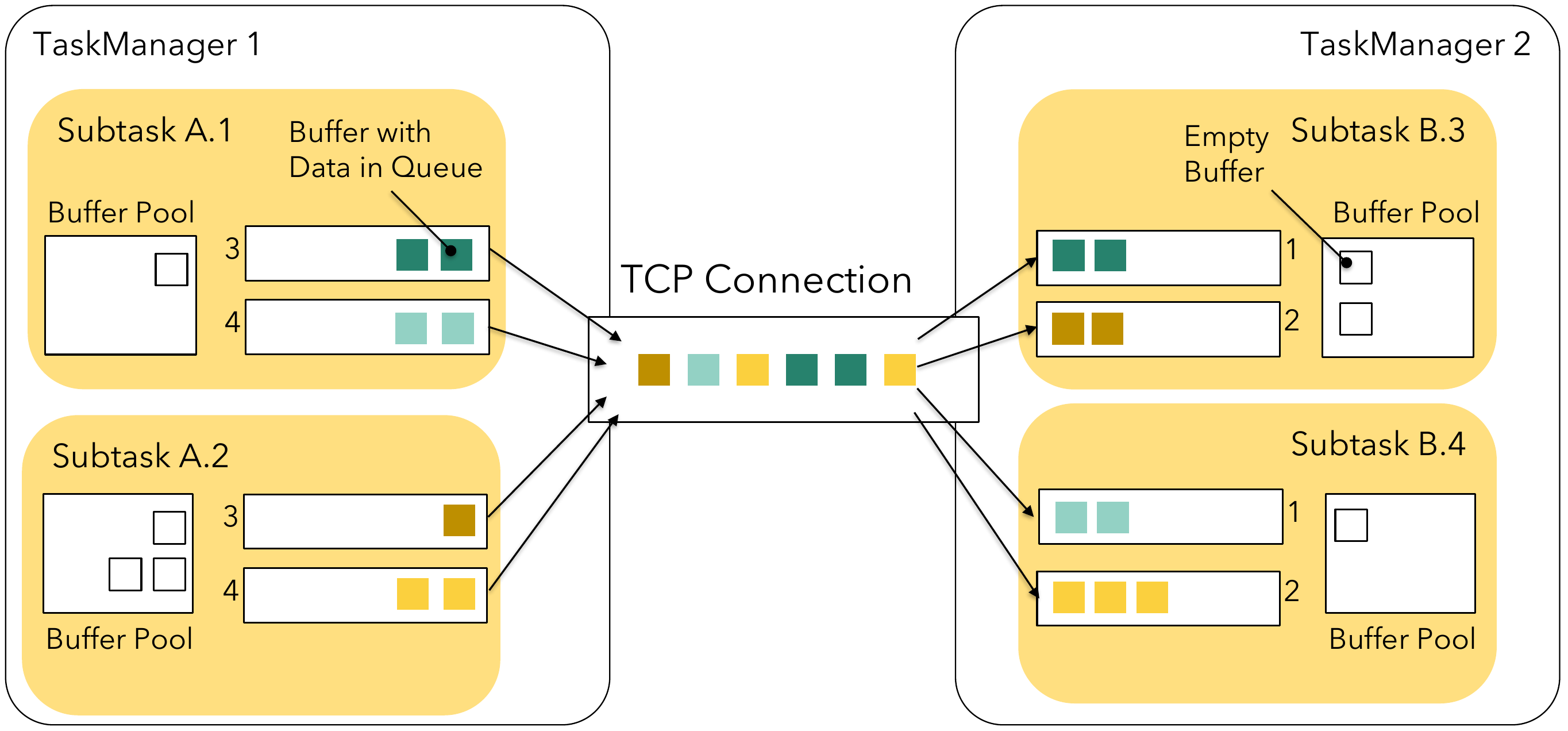
涉及到网络IO时,TaskManager将配置的内存分提供出来,抽象成NetworkBufferPool,统一管理内存的申请和释放。
每一个TaskManager拥有一个NetworkBufferPool,每一个TaskSlot拥有一个独立的LocalBufferPool, 瓜分NetworkBufferPool拥有的内存分片数。(先满足每个LocalBufferPool的最低要求,如有剩余,再按LocalBufferPool的需求比例分配)。下图是一个Flink任务网络IO的示例:
任务调度与执行
流式任务处理的场景中,对数据的延时和吞吐很敏感,Flink通过协同各个组件,推动任务高效调度与执行。
Flink Program
以官方的SocketTextStreamWordCount代码为例:
1 | object SocketWindowWordCount { |
Flink client端基于用户提交的代码,初始化执行环境,生成StreamGraph和JobGraph,并提交给JobManager执行。
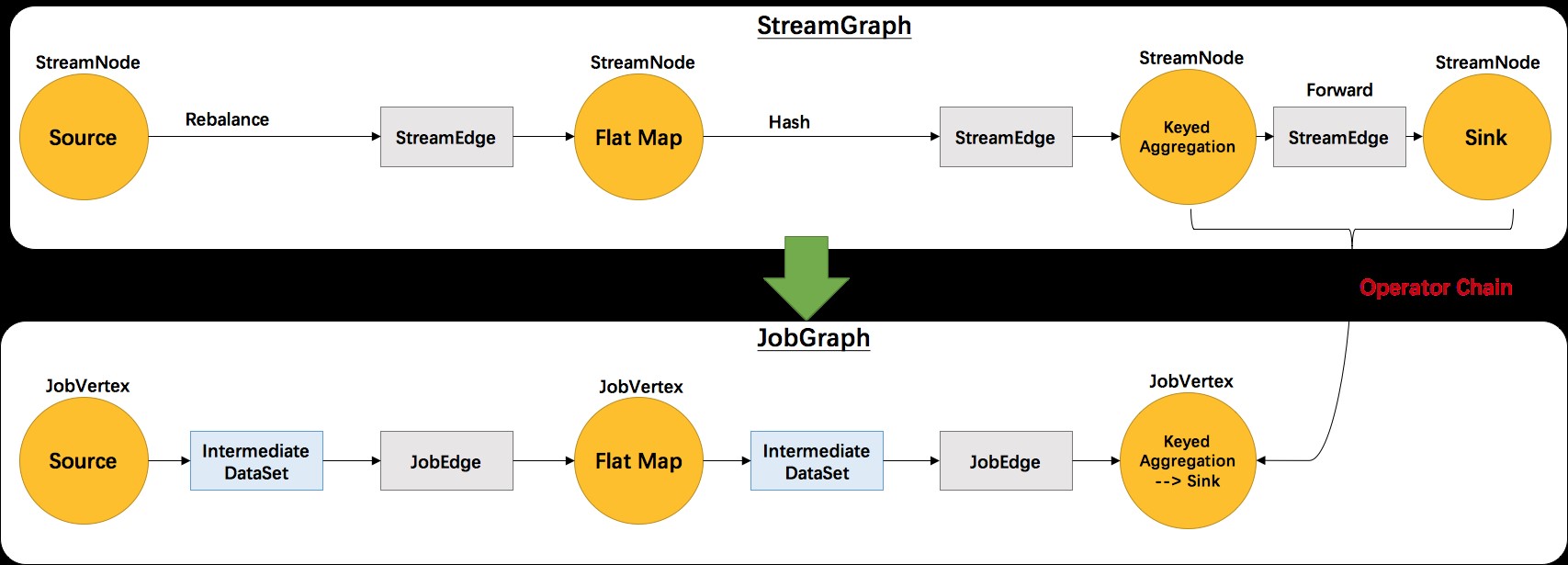
StreamGraph是任务的逻辑执行计划图,将任务执行代码中每一步解析成相应的StreamTransformation,并创建StreamNode与StreamEdge。
![]()
StreamTransformation代表了数据流生成的操作,对定义转换逻辑的StreamOperator进行了封装。
JobGraph在StreamGraph的基础上进行了优化,将可以合并的StreamNode串成chain,提高执行效率。
JobManager
接收到client端提交的StreamGraph之后,解析出对应的物理执行计划ExecutionGraph.
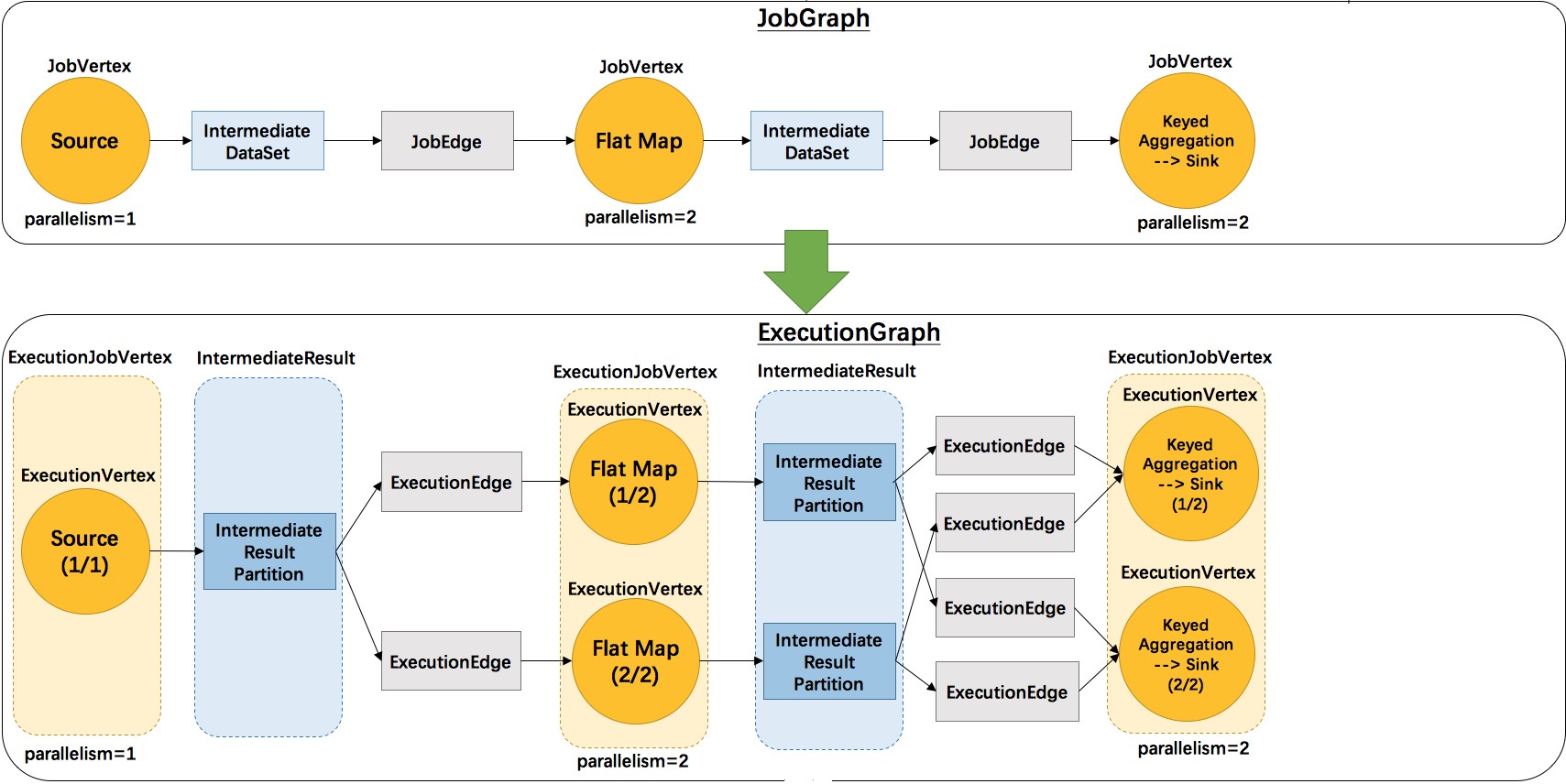
JobManger基于JobVetex和并行度信息,生成相应的ExecutionVetex, 基于IntermediateDateSet和JobEdge,生成相应的IntemediateResultPartition和ExecutionEdge。
基于ExecutionGraph的每个节点,JobManager会生成对应的执行任务,并发送给TaskManager执行。
TaskManager
TaskManager基于JobManager发来的TaskDeploymentDescriptor,生成相应的task并执行。Task执行过程主要做了以下几件事情:
- 切换任务状态
- 加载用户代码
- 向
NetworkManager注册当前任务 - 创建执行环境
- 利用反射生成invokable对象,并调用
invokable.invoke()方法执行任务。
StreamOperator中定义了数据转换的逻辑,以org.apache.flink.streaming.api.operators.StreamFlatMap为例, processElement方法,执行用户传入的userFunction, 执行flatMap方法并将结果写入collector:
1 |
|
不同的Task之间,数据传输过程如下图所示:
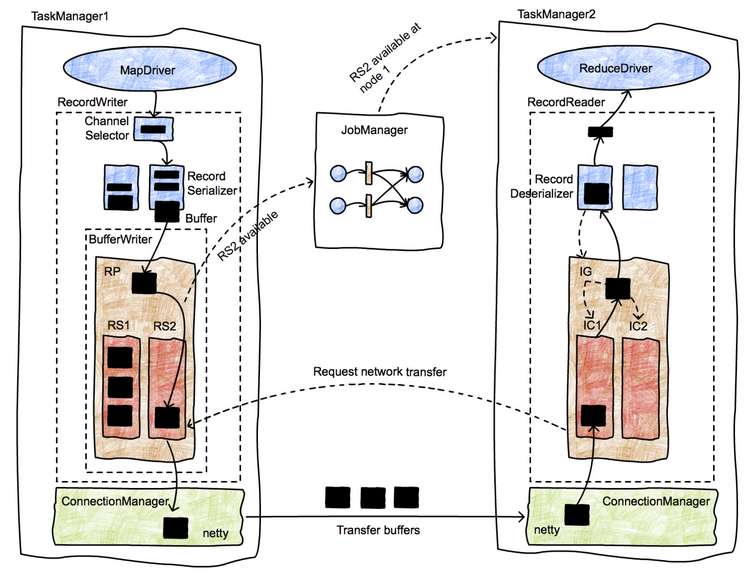
- 当前operator在完成数据处理之后,将输出交给
RecordWriter。 - 通过
ChannelSelector选择下游节点。 - 将数据序列化之后写入
ResultSubPartition。 - 触发Flush操作,将数据通过Netty通道写入对端。
- 接收端的
Netty client收到数据之后,将相应数据写入InputChannel。 - 将数据反序列化之后,交给
RecordReader,算子执行相应代码。
正确性语义
分布式场景中,数据会丢失、会乱序、会重复,出错是常态。流处理框架需要定义正确性语义,保证数据能够被正确处理,并且需要提供容错能力,保证数据处理出错的时候可以正确恢复。
时间定义
前文我们提到,流数据相对于批数据,增加了一个时间维度。为了正确的刻画流数据,需要恰当地表征这个时间维度。
时间可以有以下3中表征方式:
Event Time. 表征事件发生的时间,是事件本身的固有属性。Ingestion Time. 事件进入Flink系统的时间。Processing Time. 事件被Flink算子处理的时间。

实际的流处理任务,我们需要决定是使用event time 还是 processing time来表征事件,这两个时间之间通常是有差距的,并且受网络延时、数据流拥塞情况、系统数据处理能力的影响, 这个差距的大小是不断波动的。
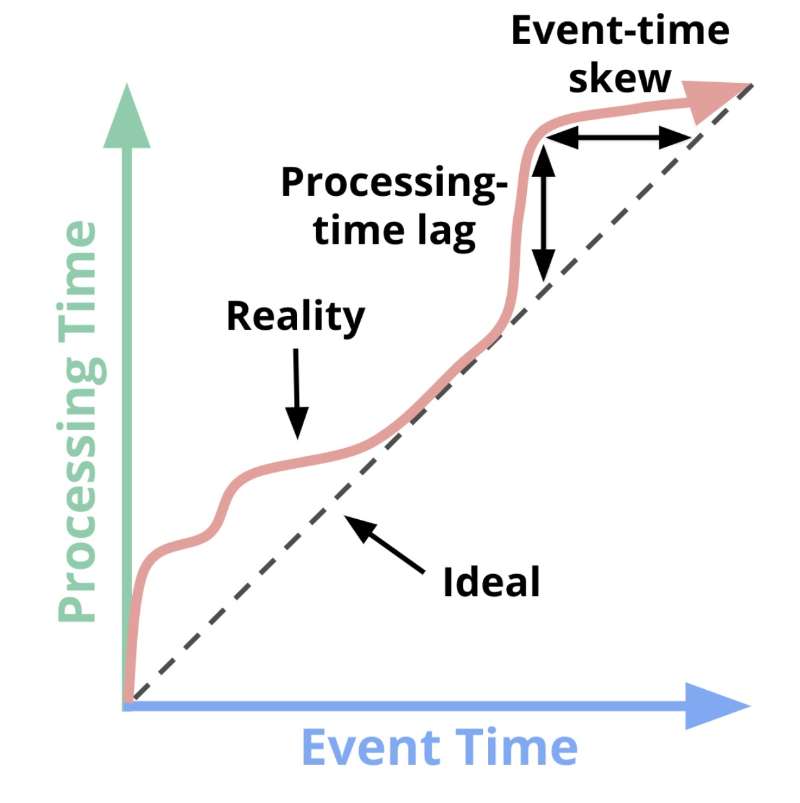
在简单的场景,比如网页统计用户访问次数(UV), 仅使用processing time 即可,在复杂的场景,比如需要考虑事件之间的先后顺序,则需要使用event time。
what
Flink到底在计算什么呢?
用一个词来说,就是变换(Transformation),具体来说,有逐个元素变换、求和、分组聚合统计、训练机器学习模型等多种变换形式,以及将多个变换组合起来合成一个任务。
where
计算在哪里进行呢?答案是窗口(windowing)。 由于流数据是时间上是无限的,我们将数据流在逻辑上做切分,分成一个个的窗口,在每一个窗口中进行数据计算。
Flink 支持一下几种窗口类型:
Fixed windows: 固定时间间隔的窗口。Sliding windows: 滑动窗口,按一定的滑动尺寸和窗口大小进行计算。比如统计最近1分钟的网站访问次数,每隔10秒钟输出一次。Sessions windows: 会话窗口。按会话维度进行统计。比如针对每个访问网站的用户建立会话,并且设定会话窗口超时阈值,假设1分钟。如果在最近1分钟之内,用户执行了操作,则将这些操作在同一个会话窗口中进行计算。
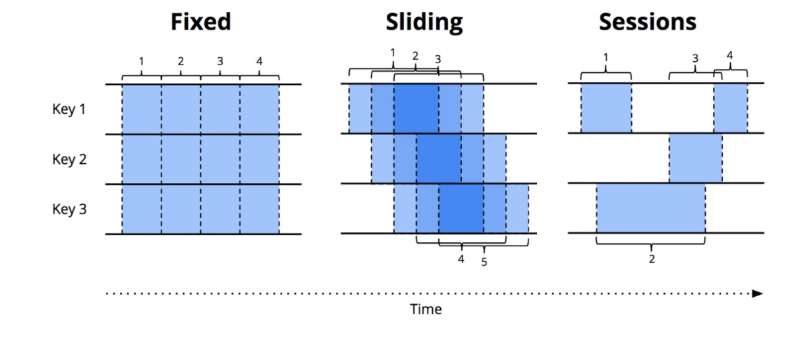
用户也可以更加自己实际的场景,自定义更加复杂的窗口机制。
when
计算结果何时输出?流式处理没法像批处理那样,读取所有的输入之后,再计算输出。Flink使用Trigger(触发器)来决定何时输出计算结果。
Trigger就像照相机的快门一样,每按一次,就产出一次快照。
逻辑上可以将每个窗口划分成多个窗格(pane), 在每个窗格结束的时刻,触发一次输出。在一些比较复杂的场景,比如数据订正(retract),后续迟到的数据导致先前窗格的计算结果需要做订正,那么一个窗格就可能产生多次输出。
Flink支持多种形式的Trigger:
Repeated update triggers: 这个是最简单的形式,按固定的频率输出计算结果。Completeness triggers: 等到数据完整之后,输出计算结果。如何定义数据完整性呢?这就需要引入Watermark的概念,后续我们会介绍Watermark。Early/On-Time/Late Triggers: 这个是综合以上两种Trigger,对于早到、准时及迟到的数据分别输出计算结果。实际实现的时候,不会无限制地等待迟到的数据,会加上迟到时间的限制,丢弃超过限制的数据。
讲Completeness triggers的时候,提到了数据完整性依赖Watermark。什么是Watermark呢?一言以蔽之,WaterMark是表征何时数据已经完整的标识。带有时间戳为X的waterMark表示,event time在X之前的数据,已经到齐了。
以开会为例,比如早上10点钟开团队会议。10点的时候,大部分参会人员已经到达,这部分人员被标记为按时(on-time)参会。但是总有一部分会迟到,为了让这部分人也能正常参会,我们需要等待一段时间,比如约定再等五分钟,五分钟之后我们正式开始,那么这个5分钟就是本次会议定义的Watermark值。

Flink支持多种形式的Watermark:
-
Perfect watermarks: 确定性watermark。如果我们能够准确的评估出数据延迟时间的最大值,就可以使用perfect watermark, 比如上文开会的例子,我们可以把watermark的值设定为5分钟。 -
Heuristic watermarks: 启发式watermark。在数据处理的过程中,Flink基于观察到的数据延时,不断的动态调整Watermark的值。适用于数据延时有较大波动的场景。Heuristic watermark可能遇到两个问题:- 太慢。数据迟到了很久,
watermark被延迟很久。 - 太快。
watermark被提前了,导致一些迟到的数据没有被正确处理。
- 太慢。数据迟到了很久,
在追求数据完整性的过程中,正确性和低延迟不可兼得。我们需要在保证正确性的前提下,尽量减少延迟。如果条件允许的话,最好使用Perfect watermark.
how
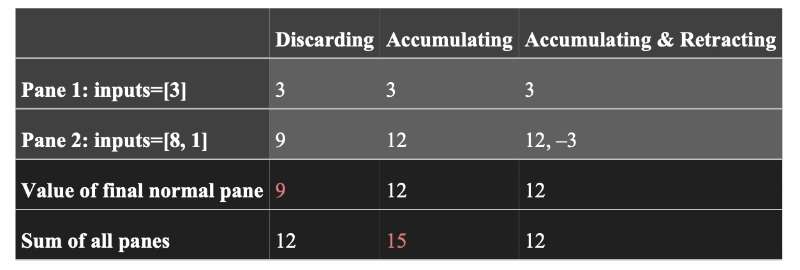
每个窗格的计算结果之间,如何彼此相关呢?有以下几种模式:
discarding- 每个窗格直接彼此独立,当一个窗格完结之后,输出结果并丢弃状态。
accumulating- 需要对每个窗格计算的结果做聚合,将窗格的计算结果持久化为状态。每个窗格完结的时候,更新已经存储的状态。
accumulating and retracting- 和accumulating类似,但是同时输出当前窗格聚合的结果(accumulating) 以及前一个窗格聚合的结果(retracting)。
一致性保证与出错处理
上文提到,分布式场景中,数据会丢失、会乱序、会重复。乱序的问题,结合Event Time 与 Watermark解决。针对丢失和重复的问题,Flink通过分布式快照(distributed snapshot),支持了Exactly Once的一致性语义。
- 分布式快照
流式数据处理,需要周期性的备份整个系统当前的状态,以便出错的时候,基于先前备份的状态进行恢复。
由于流式处理任务的特殊性,对系统状态备份,提出了特殊的要求。
- 状态的备份要足够轻量。状态备份的操作要在短时间内完成,否则会影响系统的实时性和吞吐量。
- 状态的备份需要和正常的数据处理并行。状态备份的操作不能打断正常的数据处理,像Java GC 那样,需要Stop The World才能完成整个操作,在流式处理的场景是不可接受的。
为了满足这些要求,Flink基于Chandy and Lamport算法,实现了分布式快照机制。
在正常的数据流中,Flink会周期性插入一种特殊的数据记录 - barrier,当算子处理到barrier的时候,会保存算子当前的状态到持久性存储。
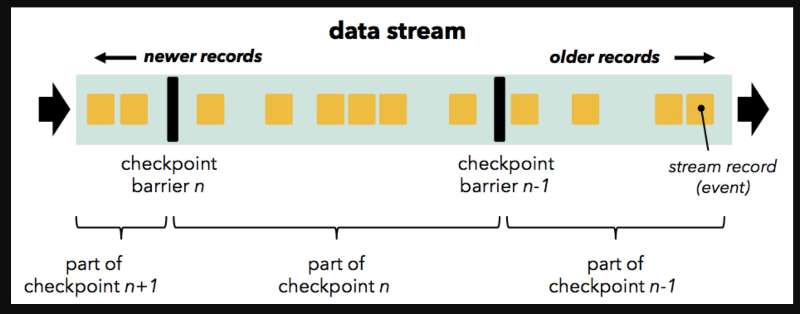
当算子包含多个输入的时候,需要对齐多个barrier(align barriers)。当算子某个输入率先接收到barrier的时候,会缓存该输入的后续数据,直到所有的输入都收到barrier之后,才会触发状态备份操作,并输出barrier到下游算子。
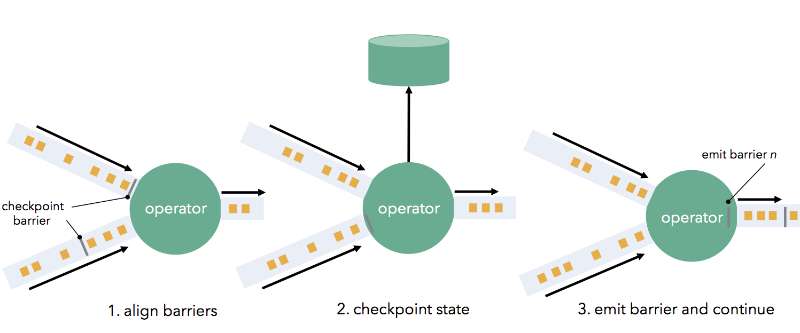
除了备份各个算子的状态生成snapshot之外,对于sink还需要执行一步额外操作 —— 将结果写入外部设备。Flink通过两阶段提交的机制(two-phase commit), 来实现这个分布式事务。
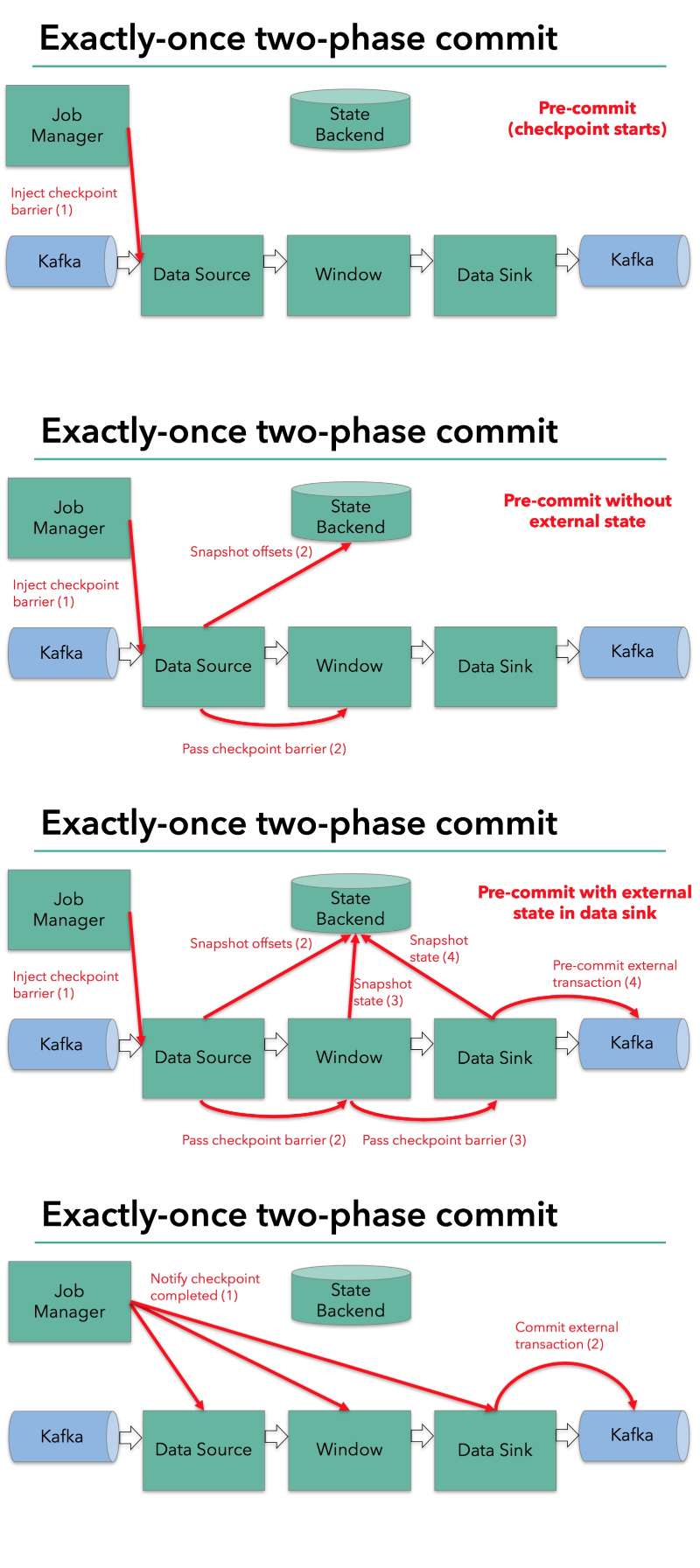
- 出错恢复
分布式快照完成之后,出错恢复就变得十分直接: 当出错的时候,系统读取最近一次成功的快照,恢复到快照定义的状态,并且source按照快照记录的点位,重新读取后续的输入数据。
流量控制
在流式处理系统中,如果某个算子处理数据的速度,持续落后于数据输入的速度,不加控制的话,就会在算子内部形成流量拥塞,严重的时候会压垮算子乃至整个系统。
流量控制的最简单方式是静态限速,通过对系统容量的评估,设置一个流量的上限阈值。业界有很多限流的组件可以直接使用,通常基于滑动窗口、漏桶、令牌桶等算法实现。
但是静态限速通常并不适用于流式处理的场景,因为任务的流量常常是动态波动的,难以预先评估出一个合理的上限阈值,需要对波动的流量进行自适应地处理。
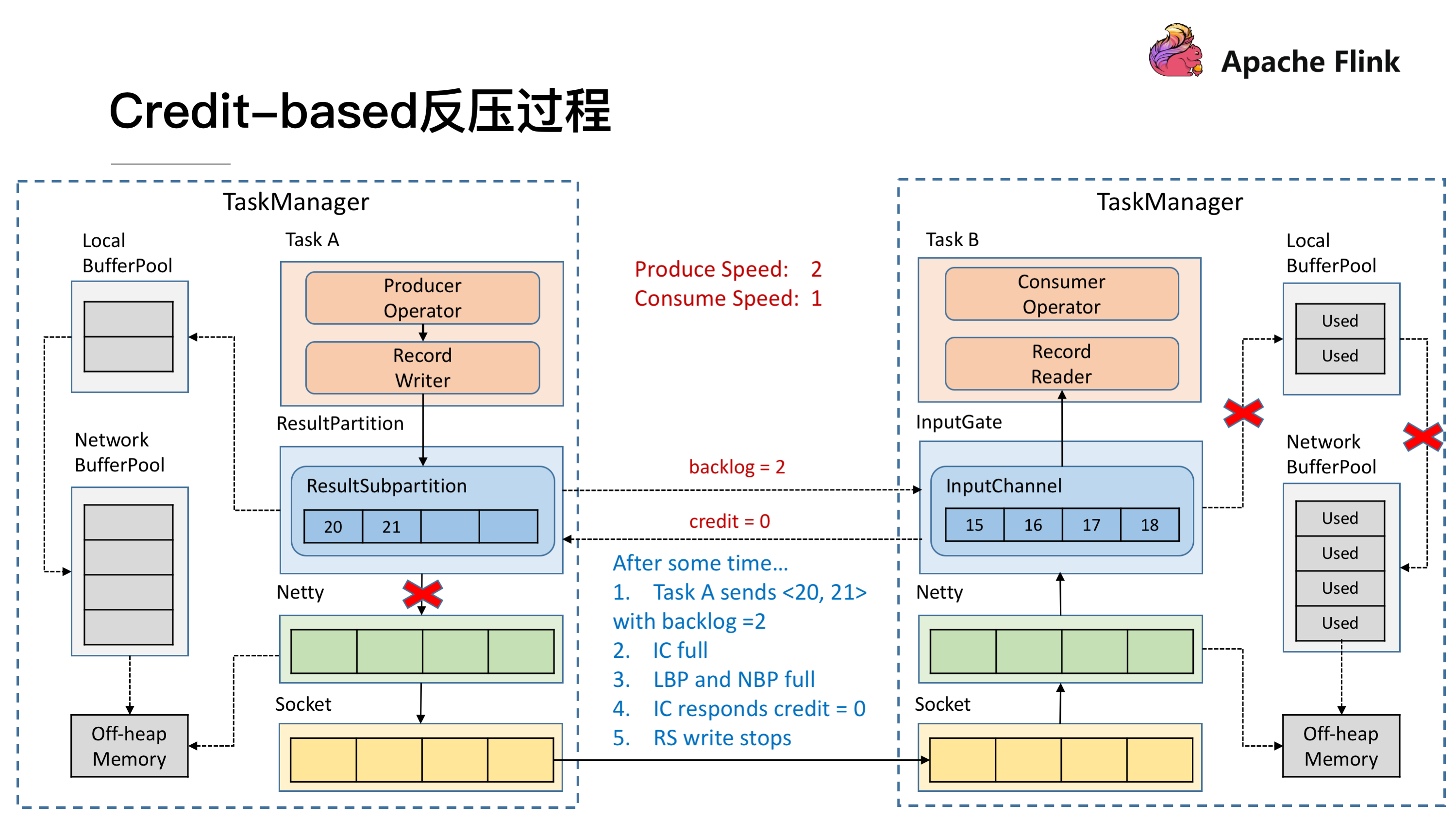
Flink底层通过TCP连接传输数据。TCP基于通过滑动窗口的机制,自带流量控制能力。在Flink1.5版本以前,是直接基于TCP实现流量控制。
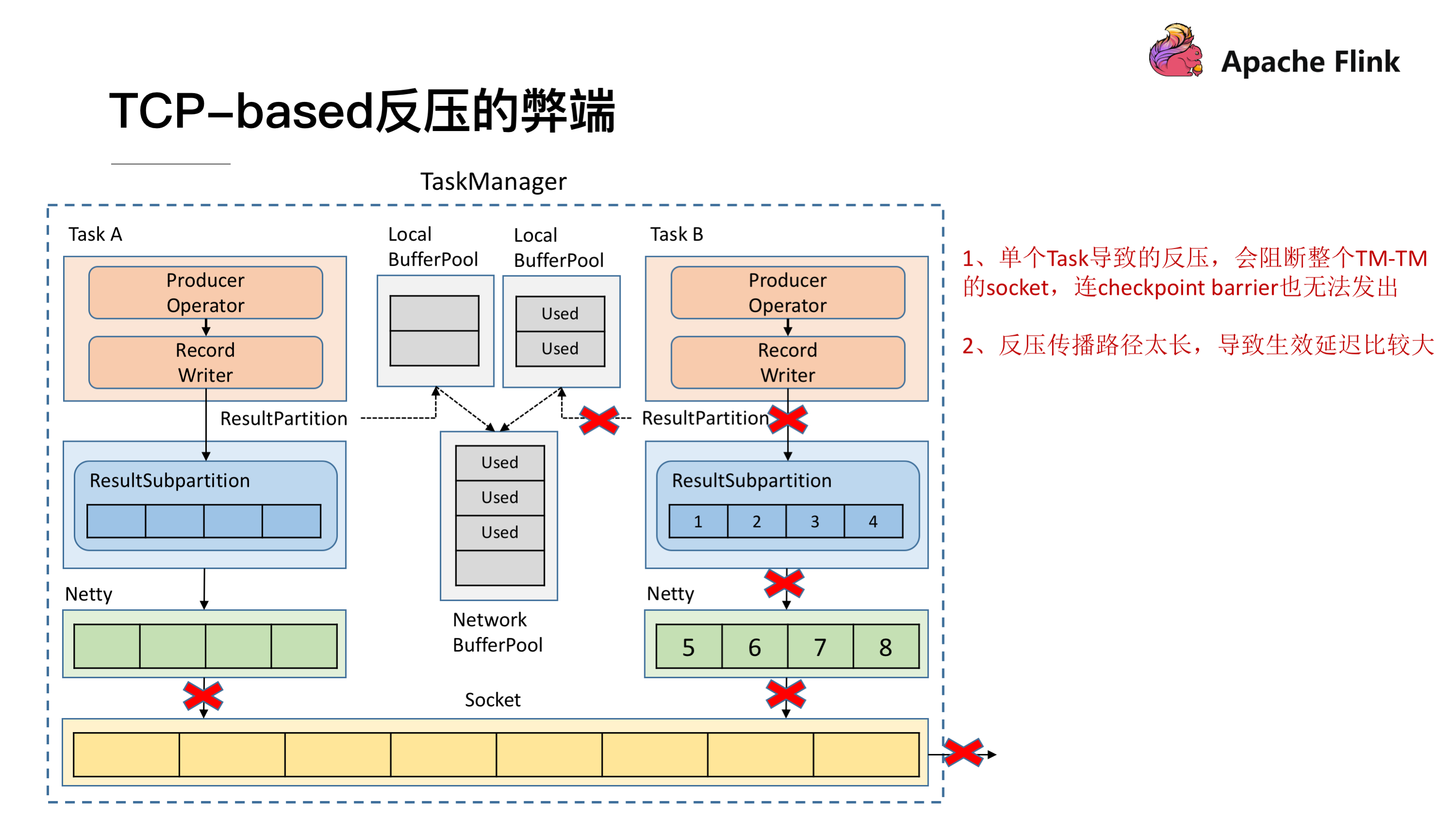
当上游的数据发送速度持续超出下游的处理速度时,InputChannel持续向LocalBufferPool申请buffer,LocalBufferPool又向NetworkBufferPool申请buffer,直至LocalBufferPool和NetworkBufferPool都无法申请到更多的buffer,InputChannel被填满,无法读取新的数据。
此时Netty会停止从Socket的Buffer中度数据,下游Socket的Buffer被填满。上游的TCP socket会收到Window=0的信息,停止发送数据。
对于上游的算子,停止向socket buffer 写数据之后,Netty达到high watermark也停止写数据,最终ResultSubPartition被填满,消耗完所以可以申请到的LocalBufferPool 与 NetworkBufferPool。
于是数据拥塞不断地向上游传递,形成反压。
基于TCP流控机制实现反压,技术上可行,但是有两个缺陷:
TaskManager管理的多个subtask, 会复用TCP连接向下游发送数据。一个subtask出现了数据拥塞,会影响其它的subtask,导致整个TaskManager都不能向下游写数据。- TCP处于传输层,基于TCP实现流控,会导致反压传播路径比较长,生效延迟比较大。
为了解决这些缺陷,在Flink1.5版本之后,引入了基于Credit的反压机制,在Flink应用层面实现流量控制。
下游的InputChannel从上游的ResultPartition接收数据的时候,会基于当前已经缓存的数据量,以及可申请到的LocalBufferPool与NetworkBufferPool,计算出一个Credit值返回给上游。上游基于Credit的值,来决定发送多少数据。Credit就像信用卡额度一样,不能超支。
当下游发生数据拥塞时,Credit减少值为0,于是上游停止数据发送。拥塞压力不断向上游传导,形成反压。
从流到批
上文提到,流式数据是批数据的一种特殊形式,流可以看成有边界的批。
流比批多了一个时间维度,使得流式处理的复杂度提升了一个数量级。所以利用成熟批处理引擎(如spark steaming)来处理流数据,只能实现近似处理。而利用成熟的流处理引擎来处理批数据,则类似降维攻击,理论上可以比较容易实现。
将批处理作为流处理的一种特殊形式,实现流批一体(stream batch unified)的处理引擎,是Flink社区一直以来的目标。在Flink1.9之前,针对流处理和批处理,分别抽象出了DataStreamAPI和DataSetAPI,期望在API层面实现流批统一。

在Flink1.9之后,社区merge了阿里巴巴的Blink分支,迎来了一次架构升级,统一使用一套引擎来处理流式任务和批任务,在上层API和底层处理引擎都实现了流批一体的目标。
更多的细节可以参考这篇文章。
总结
在系统诞生之初,正确地定义问题,对核心概念提出有力的抽象,通过合理的架构设计将复杂的问题分而治之,并给未来的功能留下充分的扩展空间,那么系统就可以沿着正确的轨道不断发展和进化,最终成长为一个优秀的系统。
Flink正是一个这样的优秀系统,能够正确、实时、高吞吐地实现流式处理。
但是任何一个系统都有边界,都有其适用的场景。不能正确地理解系统的边界,就会陷入查理芒格所说的铁锤人理论:在手里拿着个锤子的人眼里,看什么都像是钉子。
官方文档和博客,通常只会介绍系统有哪些功能,在哪些场景表现优异,但是很少会提及哪些功能是当前未实现的,哪些场景是当前系统不适用的。这部分知识,需要我们深入学习系统的原理架构之后,结合实际使用经验去领悟。
对于Flink系统来说,当我们决定引入Flink做实时数据处理的时候,可以多问自己一个问题: 用后端应用程序来做这个事情行不行, Flink可以带来什么额外的收益? 比如在OLTP场景,对数据进行随机读取,并逐条进行处理的场景,使用后端应用程序来处理看起来更加合适。而在OLAP场景,对流式数据进行聚合统计,用Flink处理就更加合适。
理解了原理和架构之后,让我们深入到实现细节,一起来看一看Flink的源码吧~