大数据处理技术的历史
为了更好地理解Flink的前世今生,让我们首先回望一下大数据处理技术的发展历史。
MapReduce
云计算的起源可以追溯到2003年,Google的三篇划时代的论文,
GFS、BigTable及MapReduce的发表,拉开了云计算的序幕。
对于分布式系统设计中面临的共同问题,比如CAP(一致性、可用性、分区容忍性)如何权衡取舍,如何进行容灾,如何高效地进行任务调度和数据处理,Google的论文中提出了行之有效且富有启发性的解决方案,这些方案对未来的大数据处理技术发展产生了深远影响。
MapReduce作为分布式计算框架,架构如图所示:

MapReduce包含了非常多的设计亮点,比如:
- 借鉴函数式编程中的优秀理念,使用Map、Reduce等无副作用的算子,使得中间的计算过程无需依赖外部状态,很容易实现并行化。
- 使用Master-Slave架构,Master节点作为大脑,负责元数据存储及任务调度,Slave节点执行具体的工作,负责数据的传输与计算。Mater节点与Slave节点各司其职,使得数据能够被高效处理。
- 数据本地化优化(Data Locality)。分布式计算中最昂贵的资源是网络带宽,通过数据本地化,使得计算尽量发生在机器本地,减少网络传输,提高数据处理速度。
Hadoop
Hadoop诞生于2005年,是对Google三驾马车的开源实现。分布式文件系统HDFS对应GFS,NoSQL数据库Hbase对于BigTable,计算框架也命名为MapReduce。
Hadoop的突出贡献在于将分布式系统的实现方案带到了开源世界,形成了健康的开源生态,通过聚合全世界优秀工程师的智慧,对自身进行不断迭代优化。基于此构建的上层工具,比如Pig、Hive,降低了大数据分析的门槛,让数据分析人员能够通过类似SQL的简单方式,对大数据进行分析挖掘。
Storm
Apache Storm诞生于2010年,是第一个被业界广泛使用的流处理系统。在批处理系统中,子任务出错的时候,可以通过简单地重新读取相关的输入数据,重新执行该任务,重建相关的结果集,但是在流式处理系统中,由于输入的是时间上无界的数据流,没有明确的起点和终点,所以无法向批处理那样,通过重新执行出错任务来容错。
Storm使用ACK机制进行容错,其原理如图所示:
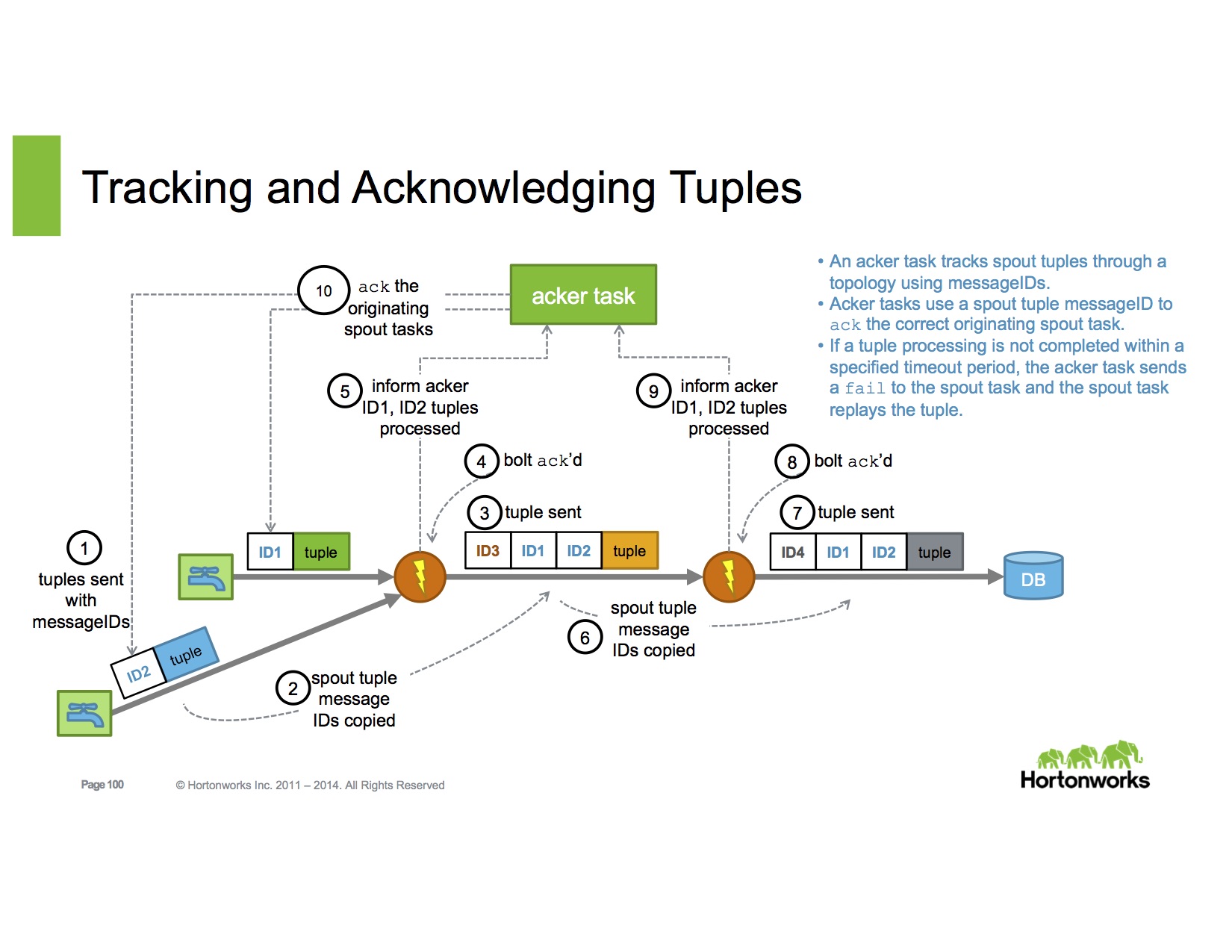
Storm中使用Acker Task,负责跟踪消息的处理。对于源头(spout)产生的一条记录,如果下游节点(Bolt)成功处理了该记录,则会向Acker发一条确认消息。如果所有的下游节点都发送了确认消息,则认为该记录被成功处理。如果下游节点回复了处理失败,或者在给定的超时时间内未做回复,则任务该记录处理失败。
当记录处理失败时,Storm会发起重试,所以Storm的一致性保证是At Least Once 而非 Exactly Once,需要用户程序对可能的重复数据做幂等处理。在下游节点存在反压(backpressure)的时候,由于数据处理不及时导致Ack超时,会使得整个系统中出现大量重试,降低了吞吐量。
总而言之,Storm对流式数据的处理,做到了低延时,但是牺牲了一致性和吞吐量。
实际的大数据处理业务场景中,人们希望系统同时具有低延时和准群性,单靠Storm无法满足要求。于是便诞生了Lambda架构,将Hadoop批处理能力和Storm流处理能力结合起来,hadoop负责输出高延迟但准确的结果,Storm负责提供低延时但不准确的结果,系统整体输出低延迟并且最终一致的结果。其架构如图:
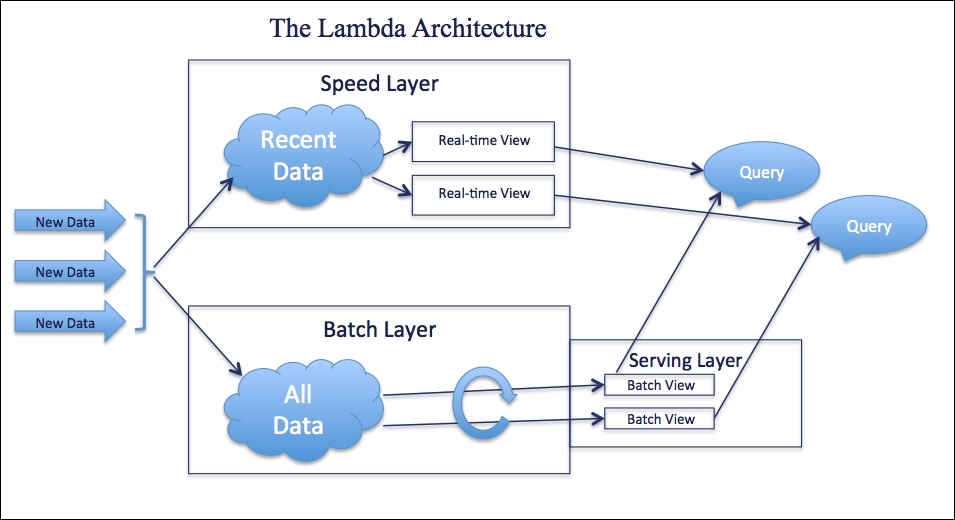
Lambda架构在业界大受欢迎,但是也存在着一些缺陷:
- 一致性保证。在流处理模式下,最终一致性意味着,在绝大部分时候,看到的数据结果可能是不准确的,这会影响用户对数据的信任。如果我们需要看到一直准确的数据,那么就需要达到强一致性,需要保证数据处理Exactly Once。
- 复杂性。需要分别为批处理和流处理维护两套代码,这两套代码要做的事情大部分是相同的,但是代码的外在形式上却存在很大差别,增加了维护的成本。
针对这些缺陷,业界也提出了很多优化方案,比如Lambda Plus架构。
Spark
Spark在2009年诞生于加州大学伯克利分校的AMPLab,通过引入弹性分布式数据集(RDD)的理念,在内存中完成大数据处理,大大加快了处理速度,成为了hadoop的实际继承者。基于对大数据集快速处理的能力,spark在迭代处理、机器学习、图计算领域都有优秀的表现。
Spark在批处理领域非常地成功,那么是否可以把这成功的设计,低成本地复制到流处理领域呢?这便是Spark Streaming的由来。

Spark Streaming的思想很简单,将数据流按时间窗口切分,每一个窗口内的数据处理都是一个微批(micro-batch)任务,如果某个窗口内数据处理失败,则重新执行该微批任务即可。
在处理有序数据流或者事件时间无关的数据流时,spark streaming 可以提供强一致性保证。 由于批处理先天的优势,spark streaming任务可以实现高吞吐量。
spark streaming的缺陷在于,由于使用了微批,在实时性上不如真正的流处理,数据延迟通常在秒级乃至分钟级。在流量控制方面,在系统中出现反压时,会导致微批的处理超时,大量的批次需要排队等待,单个微批需要处理的数据量增大,在系统内部出现拥塞。
Flink
终于轮到本系列博客的主角 – Flink登场了。Flink诞生于2015年,针对流式处理提出了许多创新设计,引领着流式处理技术的发展。Flink的主要特性:
- Exactly Once保证。采用分布式快照(Distributed Snapshots)机制,对整个系统的状态做轻量级快照(Checkpoint),在节点出错时能够快速恢复到先前正确的状态,为数据处理提供强一致性保证。
- 完备语义的流处理能力。一致性问题是流处理和批处理需要面对的共同问题,除此之外,还有一些问题是流处理场景所特有的,比如数据的乱序及迟到,Flink通过引入Event Time、WaterMark、Trigger 等机制,解决了这些特有问题。
- 低延时。通过采用真正的流式处理,而非微批方式,Flink可以实现亚秒级的实时性。
- 高吞吐。Flink的快照生成机制十分轻量,并且在后台并发执行,不会影响到对正常数据流的处理。当系统出现反压时,采用基于Credit的机制控制源头数据流量,防止系统内部出现拥塞。Flink系统的吞吐量可以达到Storm的300倍。
- 高效的编程模型。Flink的流式处理接口简单清晰,用户可以很方便定义自己的业务处理逻辑。Flink还提供了一套和流处理形式一致的批处理接口,使得相同的代码可以同时用于流处理与批处理场景,实现了流批一体的目标。基于流和表的概念模型转换,Flink抽象出一套Table&SQL API,让用户可以通过类似SQL的方式处理流式数据。

后续的文章中,我们会详细分析这些特性的实现细节。
为什么需要流式处理
在很多对实时性要求不高的场景,批处理完全可以满足需求,结果可靠并且消耗资源少。但是对数据实时性要求较高的场景,如果我们不能提供很好的流处理方案,那么数据背后的信息就无法及时呈现,数据的价值流动就会陷入阻塞。
Flink针对流式数据处理提供了一系列优秀的设计方案,现在让我们一起踏上Flink的探索之旅吧!