什么是 Harness
随着大模型能力的迅速发展,工程师们在AI 的辅助下,能够以数倍乃至数十倍的效率,高效地产出工程代码。
模型的能力本身已经很强大,但是同一个模型,在不同的使用方式下,输出的质量差异巨大。如果不加任何约束,一旦模型产生了某种幻觉,很容易沿着一个错误方向迅速偏离。
模型本身没有问题,问题出在怎么驱动模型上面。我们需要给模型加上护栏,保障AI能够实现持续产出生产级可用代码的目标。于是 Harness Engineering的理念应运而生。
Harness Engineering 不是一个编程工具或者框架,和敏捷编程类似,它是一种 AI 编程实践理念,是围绕 AI Coding Agent 设计和构建约束机制、反馈回路、工作流控制与持续改进循环的系统工程实践。
Harness 字面上有马具的意思,这是一个有趣的隐喻,大模型像一匹野马,能日行千里,但有时会不受控制,所以需要 Harness 的约束,让它跑在正确的方向上。
起源和发展
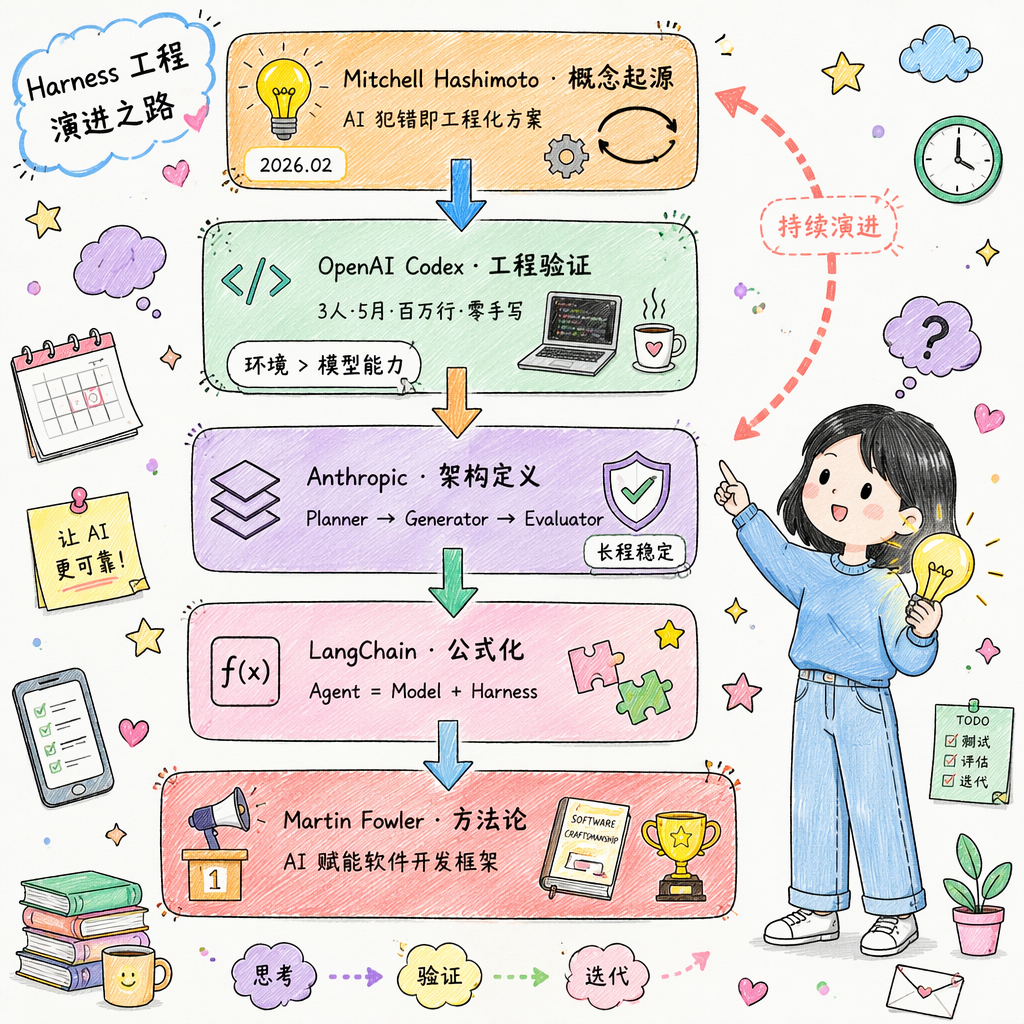
Harness 概念的源头,由 HashiCorp 联合创始人 Mitchell Hashimoto 于 2026 年 2 月 5 日提出,核心理念是:每当 AI 犯错,就工程化一个方案,让它永远不再犯同样的错。通过反馈驱动,系统性地解决问题根源。
OpenAI内部一个最初仅3人的工程师团队,使用Codex Agent在五个月内构建了一个百万行代码的真实产品,全程未手写一行代码。团队发现,最困难的挑战不是模型能力不足,而是如何设计让智能体稳定工作的环境、反馈循环和控制系统。
Anthropic 将 Harness 定义为支撑复杂 AI Agent 运行的外部框架、控制结构与编排系统,提出了 Planner -> Generator -> Evaluator 架构,来保障 Agent 在长程任务中稳定运行。
LangChain 作为核心推动者,提出了公式 `Agent = Model + Harness`,将 Harness 定义为除了模型本身之外的每一行代码、配置和执行逻辑。
软件工程思想领袖 Martin Fowler 的站台,将 Harness Engineering 从流行词汇提升到了主流工程方法论的地位,指出 Harness Engineering 是对 AI 赋能软件开发的框架性阐述。
为何需要Harness Engineering
如果我们裸用 AI Agent 进行编码,会遇到以下核心挑战:
上下文管理困境
大模型本身是无状态的,模型无法记住上一次调用的内容,依赖上下文传入模型决策所需要的信息。
一个典型的上下文窗口,通常由以下几个部分构成:
-
系统提示词(System Prompt)
-
对话历史(Conversation History)
-
当前用户输入(Current User Message)
-
工具调用与结果(Tool Use & Results)
-
检索增强内容(RAG,可选)
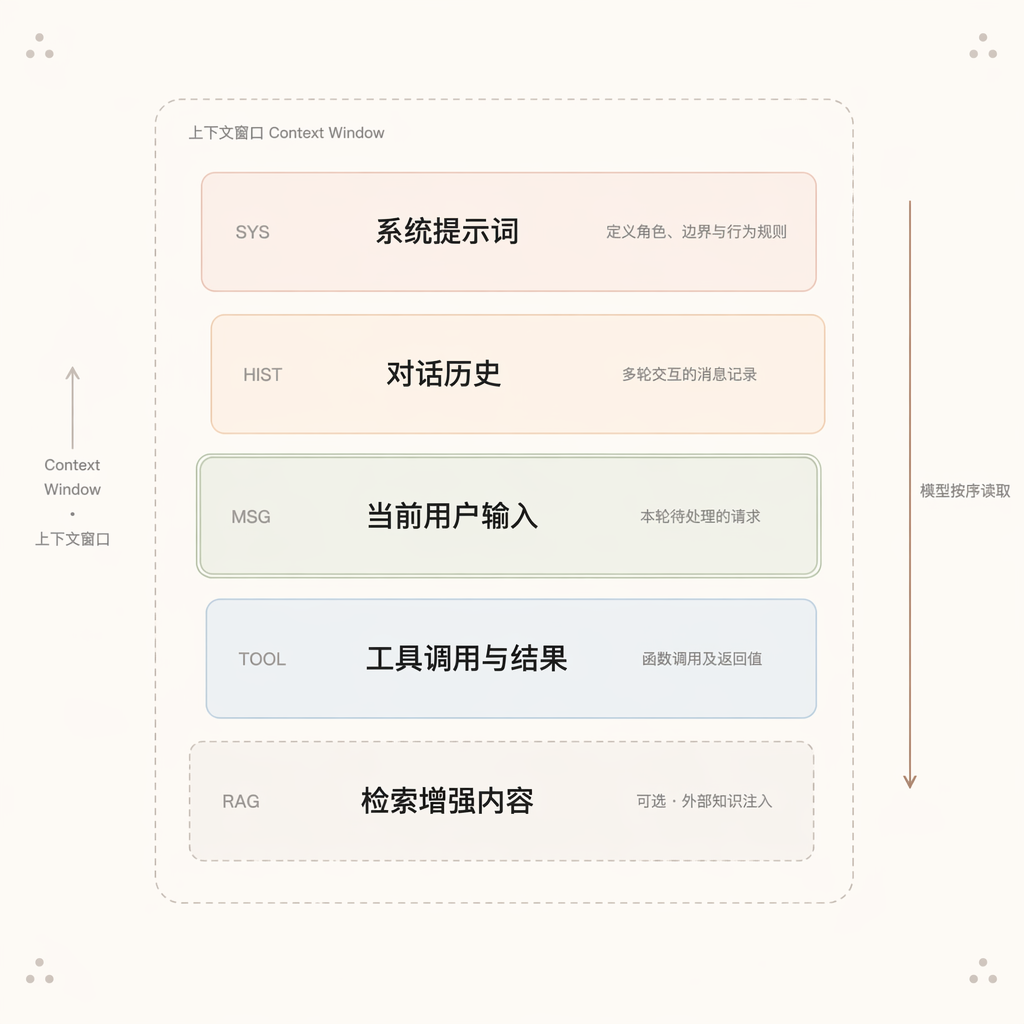
上下文窗口长度是有限的,即使是 1M token 的模型,也放不下一个中型项目的代码量,Agent 无法自主决定什么该看,什么不该看。
当大量的仓库内容被塞进上下文时,上下文的质量(信噪比)急剧下降,关键信息被淹没,模型注意力被稀释,导致回答质量降低。
工具系统与环境安全
大模型本身不能执行任何操作,它只能生成文本。读写文件、执行系统命令,都需要外部工具的支持。
一些操作具有破坏性,比如 `rm -rf`、`git push --force`、`DROP TABLE`,Agent 可能会因为环境而执行这些危险操作。一些操作会涉及敏感数据,Agent 可能会把 `.env` 中的密钥文件发送到外部服务。
模型幻觉
幻觉是大模型的固有属性,在编码场景,模型幻觉可能对产生的结果造成负面影响。
Agent 可能会基于训练数据猜测项目结构,编造不存在的 API/函数/文件路径。如果生成的代码,没有经过 lint 检查、单元测试验证,错误会逐渐累积。
状态与记忆断裂
如果不做显式管理,Agent 无法记录历史的状态,保留历史的记忆。每次 Agent 对话从零开始,不记得用户的偏好、项目的约定。历史上犯过的错误,无法沉淀为团队知识,导致错误重复发生。
对于长程任务,Agent 做到一半,上下文被截断,导致不知道当前做到了哪里,Agent 陷入失忆状态。会话不是记忆,上下文窗口也不是项目状态。对话可以压缩,可以截断,也可以被后续信息稀释。模型在第十轮对话还能记得第一轮的内容,从来都不是一个可靠前提。
任务规划与分解能力不足
Agent 倾向于一次性输出完整方案,但是在处理复杂任务时,脱离了分步执行和中间验证环节,寄希望于一步到位是不现实的。
多个子任务在运行,如果没有对任务之间的依赖做合适的解析,子任务之间只能串行执行。
如果一个任务走错了方向,也无法回退,只会沿着错误的道路越陷越深。
输出质量不稳定
如果项目中缺乏统一的规范约束,则每次生成的代码风格、命名规范等可能不同,项目的 lint 规则、测试规约也无从遵守。
Agent 常常倾向于过度设计,向工程中添加不必要的抽象、实现分支、错误处理。
每次 Agent 生成代码,都可能引入少量的风格不一致、冗余逻辑或次优实现。单次看起来无关痛痒,累积起来却会让代码库逐渐腐化(Code Rot),软件熵持续累积直至复杂度失控。
裸用 Agent 写代码,质量控制几乎完全依赖人工 Code Review。但是由于 Agent 的产出代码的速度远超人工审查速度,质量瓶颈就从"写代码"转移到了"审核代码"。
Harness Engineering实践
Harness Engineering 的本质是:把 LLM 的概率性输出,通过工程系统转化为确定性的、安全的、可验证的软件工程操作。
每一个工程实践方案都在回答同一个问题——如何让一个"聪明但不可靠"的组件,变成"聪明且可靠"的系统。
上下文工程
核心目标是在正确的时刻把正确的信息放入上下文窗口。
-
上下文分层。每一层有不同的生命周期和加载策略,避免一次性灌入所有信息。对于项目级别的上下文,如memory 文件,按需注入。对于任务级别的上下文,比如当前正在操作的文件、搜索工具返回的结果,动态加载进上下文。对于对话历史,按需动态压缩。
-
按需加载。不预先加载整个代码库,而是提供项目知识文档,以及搜索和读写工具,让Agent自主决定需要加载哪些内容到上下文。
-
上下文压缩。当会话接近窗口上限时,自动触发压缩,整个过程对用户无感知。压缩时保留当前修改了哪些文件、任务进度、用户的关键指令,丢弃掉中间探索细节。
在实际项目的实践中,通过一个全局的AGENTS.md文件(123行),作为代码库整体知识的索引和地图。按系统架构知识、通用知识、规范知识、产品领域知识这几层,分层构建了项目知识库。
Agent 在编写代码时,基于渐进式披露的方式,按需加载项目知识。
工具编排与环境隔离
为了让 Agent 高效调用所需工具,引入了以下 Harness 工程实践:
-
通过cli、mcp、skill 扩展工具支持,各个工具需要满足原子性和可验证性。
-
工具执行的结果,完整返回,如果执行失败了,不直接终止流程,而是让 Agent 基于错误信息自己尝试修正。
-
对于一些危险操作,可以放到沙箱中执行。在项目约束中,强制要求用户确认之后才能执行高危操作。
在实际项目的实践中,通过 MCP 工具读取钉钉&语雀文档,通过 superpowers 配套的 skill 进行代码验证工作,代码 Agent 在运行过程中,按需调用已安装的工具。
规范约束
模型的训练数据是静态的,但是项目代码是动态的,为了避免项目代码偏离最初的设计目标,需要通过 Harness 显式地给 Agent 加上规范约束。
可以强制让 Agent 基于客观事实(读取的文件内容、搜索工具返回的结果)作为行动的依据,禁止随意猜测。
让 Agent 遵循 写代码 -> 编译 -> 规约检查 -> 单元测试 -> 修复问题 的循环,通过准确的反馈保障代码的正确性。
在实际项目的实践中,沉淀了 PRD 文档规约、任务执行规约、技术实现规约等一系列 Harness 规范约束,利用这些强有力的约束避免 Agent 跑偏。
状态持久化与记忆系统
引入多层持久化架构,会话内的历史随上下文增长自动压缩,通过task文件跟踪记录当前任务进度,项目级别的约定和配置沉淀到项目知识文档中。
构建结构化的记忆系统,分类管理结构化条目,记录用户的背景、偏好等信息,通过索引文件MEMORY.md管理,按需加载。
在实际项目的实践中,借鉴了openspec 的archive 命令,每次需求开发完成之后,通过archive命令将新知识更新到项目知识库,保证代码库知识始终和最新的代码内容对齐。
规划与任务编排
先列计划再执行,给 Agent 提供明确的完成标准,通过 Planner -> Generator -> Evaluator 的循环,将复杂的大任务拆分成小任务,跟踪执行进度。
通过任务的拆分,梳理出任务之间的依赖关系,编排任务执行顺序,使得互不依赖的子任务,由子 Agent 并发执行,各个子 Agent 上下文互相隔离,不污染主 Agent 上下文窗口。
在实际项目的实践中,拆分出的子 task,会明确标记出上下游依赖关系,以及是否可以并发执行。对于可并发执行的子任务,启动子 Agent 减少任务执行总时间。
输出质量保障
约束 Agent 在编码任务完成之后,在关键节点执行检查,强制执行规范校验、单元测试验证。
重点是把错误的 fix,沉淀到系统知识库中,让 Agent 在后续执行类似任务时,不再重复犯同样的错误。
需要注意的是,执行审核校验的 Agent,要使用和编码不同的 Agent。让编码 Agent 自我审查,会停留在自我感觉良好的状态,换一个新视角才能有效发现设计缺陷。
检查的内容,除了代码规约和单元测试之外,也要审核系统设计的可能问题,持续降熵防止代码腐化。
在实际项目的实践中,开发完成之后,会自动执行规约校验和单元测试,并手动调用superpowers的review skill,审核设计问题。
后续需要把这一套校验测试机制,放到我们的持续交付流程中,打造AI delivery流水线,每次代码提交后自动触发规约检查、单元测试执行、架构设计校验,让后台 Agent 自动扫描并提交修复 PR,形成自动化的"Entropy Garbage Collection"机制。
真正成熟的 Harness,有“把一次偏差转成长期约束”的能力,打造一个持续进化的工程系统。
反模式
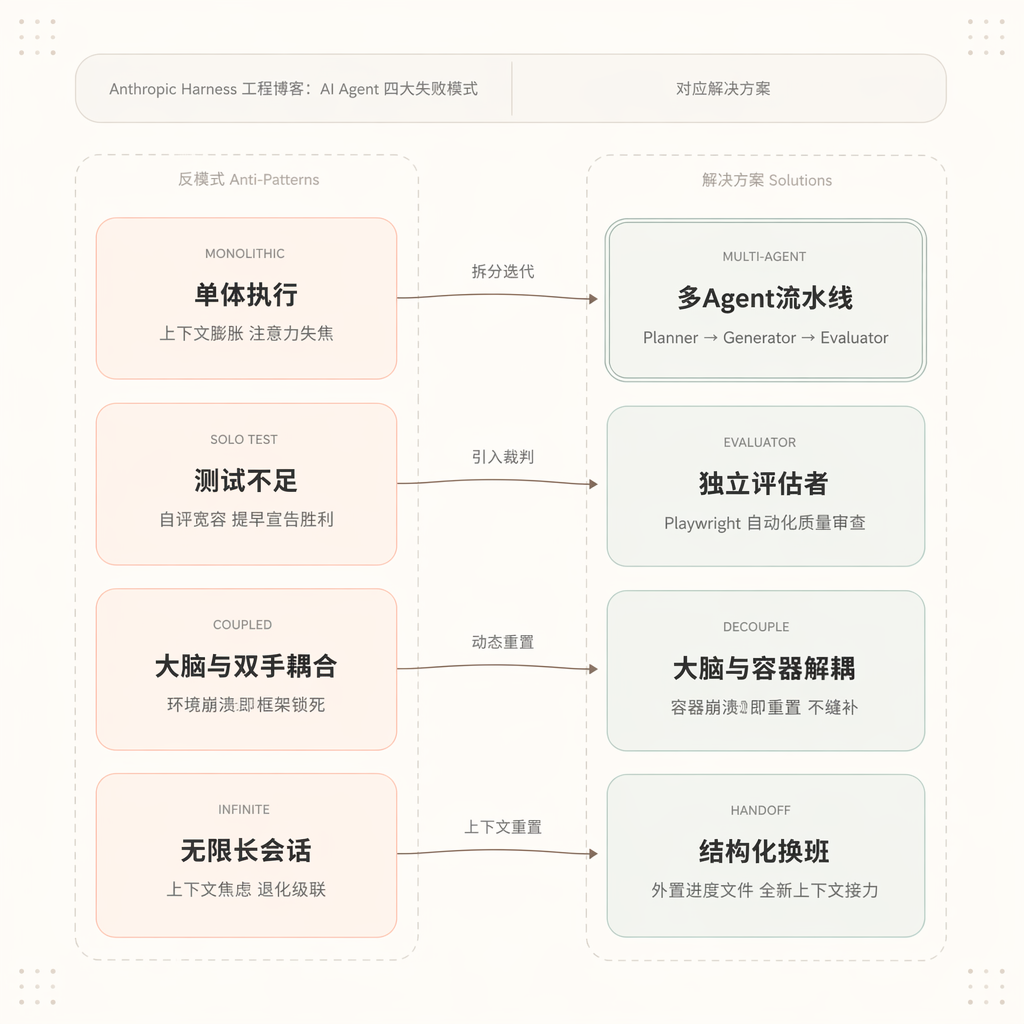
实际的 AI coding 开发过程中,存在着一些反模式,让 Agent 无法产出高质量的代码。Anthropic 在其 Harness 工程博客中,总结了 Agent 在复杂项目中的四种典型失败模式及其对应的解决方案:
One-Shotting & Monolithic Execution 单体执行
如果让模型在单次对话中,执行一个庞大且复杂的任务,模型会面对上下文膨胀和注意力失焦的问题,导致输出质量直线下降。
[解决方案] 实现一个多 Agent 的 pipeline,引入 Planner、Generator、Evaluator 这 3 个 Agents,拆分需求并迭代开发。
Superficial & Late-Stage Testing 测试不足
如果让单 Agent 既当生成者又当裁判(Solo Harness),Agent 会表现出对自己的产出极度宽容,并提早宣告胜利。
[解决方案] 引入独立的Evaluator对结果进行评估,通过 Playwright 等自动化工具进行严格的质量审查。
Tight Coupling 大脑与双手紧密耦合
如果将 LLM 运行时与执行环境(Sandbox 容器)混在一起,一旦网络超时、环境崩溃或遇到恶意代码,整个 Agent 框架就会彻底锁死。
[解决方案] 将大脑与双手解耦,Harness 不再驻留在容器内部, 容器挂了,Harness 直接捕获错误并动态重置一个干净的新容器,而不需要去缝补坏掉的环境。
Treating Sessions as Linear and Infinite 无限长会话
当 Agent 执行跨越数小时或数天的任务时,模型会遭遇上下文焦虑(Context Anxiety),随着上下文窗口变长,其理解和推理能力会发生“退化级联错误”。
[解决方案] 引入带结构化交接的完整上下文重置机制。Agent 像人类软件工程师“换班”一样,在旧会话耗尽前,将当前进度、未完工的 Feature List 写入外置的文件中,然后彻底清空并重置 LLM 上下文,由一个拥有崭新记忆的 Fresh context 实例读取这些外置状态继续工作。
结语
Harness 的本质是外部化的质量保障体系。Harness 的价值不在于让 Agent 变得更聪明,而在于让 Agent 的错误变得可控、可发现、可修复。
模型在持续吸收 Harness 的能力,为 Harness 做定制化训练。工具调用(function calling)最初是 Harness 层的设计,现在已经成为了模型的原生能力。规划、多步推理、自我纠错——这些能力正在通过后训练被内化到模型权重里。随着模型越来越发展,Harness 可能会越来越薄,也可能会出现新的 Harness 配套工具,但是 Harness 背后的工程思想,会在 AI 时代持续产生价值。
有人的地方就有江湖,有 Agent 的地方就有 Harness,人本身就是最重要的隐式 Harness,人在为 Agent 建设 Harness 的同时,本身也在成为更好的 Harness。
参考文章
-
[Harness engineering: leveraging Codex in an agent-first world]https://openai.com/index/harness-engineering
-
[Harness engineering for coding agent users]https://martinfowler.com/articles/harness-engineering.html
-
[The Anatomy of an Agent Harness]https://www.langchain.com/blog/the-anatomy-of-an-agent-harness
-
[Harness design for long-running application development]https://www.anthropic.com/engineering/harness-design-long-running-apps
-
[Effective harnesses for long-running agents] https://www.anthropic.com/engineering/effective-harnesses-for-long-running-agents
-
[Caling Managed Agents: Decoupling the brain from the hands] https://www.anthropic.com/engineering/managed-agents