引言
最近阅读了《Designing Data-Intensive Applications》,结合自己的理解,总结一些心得体会。
背景
我们正处在信息爆炸的互联网时代,随着移动互联网、云计算、IOT等领域的不断发展,数据的总量和复杂度在飞速增长,目前全球每天约有2.5quintillion(10亿乘以10亿)字节的数据产生(2020.3月数据)。
大数据是互联网时代的石油,蕴藏着无限的价值。
收集海量数据、发掘数据价值,是互联网公司的核心增长手段,数据智能已经成为推动智能商业增长的核心引擎之一。
然而,从信息匮乏过渡到信息爆炸时代,从1989年web诞生至今,这场变迁是在短短30年内发生的。我们还没有做好充分准备,就已经被海量的数据所包围。如何充分释放出大数据的价值,让数据成为资产而非负担,是每一位大数据系统参与者,都需要思考的问题。
希望通过本系列文章,能够系统描述,大数据系统设计领域的核心理念、架构方案与具体实现。
数据密集型应用
数据密集型应用(data-intensive application), 和计算密集型应用(compute-intensive application)相对应。计算密集型应用的瓶颈在于CPU的处理速度,而数据密集型应用更大的挑战是数据———— 数据量、数据的复杂度以及数据的变化速率。
我们平时接触的很多系统,都属于数据密集型应用,典型的有:
- 数据库
- 缓存
- 搜索引擎
- 流式处理。A应用发出一条消息,B应用进行异步处理。
- 批处理。对数据进行周期性地分析统计统计。
为什么需要理解数据密集型应用
现代的数据系统,基本都具有丰富的功能和详尽的文档,我们直接拿来使用就可以,为什么需要去深入理解概念和原理呢?毕竟实际工作中,几乎没有需要从头设计一个数据库、搜索引擎的场景。
但是作为开发者,在现实场景中,需要解决的问题是千差万别的,只有掌握了底层的原理,才能在技术选型和架构设计时,找到最切合当前场景的技术方案,并加以整合与创新,解决实际问题。
对于数据库、消息队列、缓存、搜索引擎等各种数据处理系统,我们不仅需要分别进行探索研究,还需要把这些系统作为一个整体进行思考,这是因为:
-
系统间的功能边界,正在变得越来越模糊。比如Redis,本身是一个基于内存的分布式数据库,实际场景中经常被用作分布式缓存,但是也可以作为一个简单的消息队列使用。
-
实际场景的复杂度越来越高,单个系统常常不足以解决问题,需要将多个系统拼装组合起来。以下是一个实际业务场景的架构示意图:
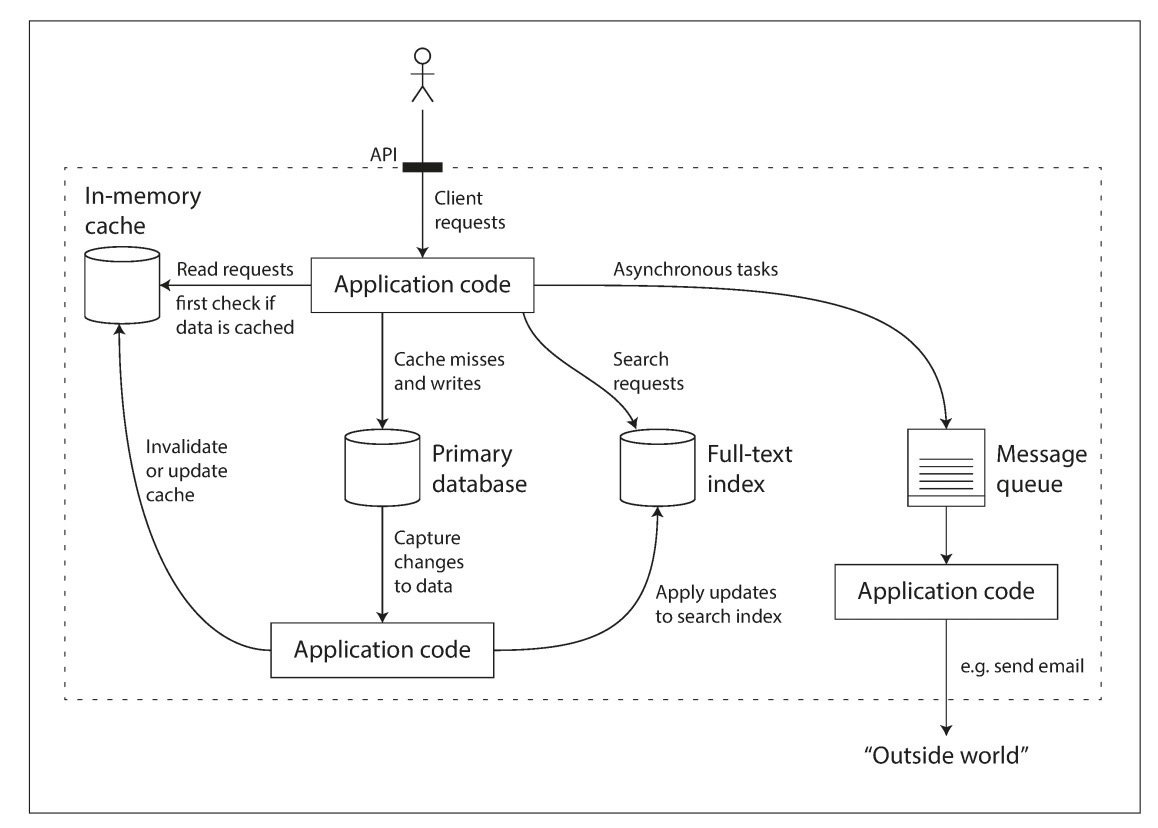
数据密集型应用设计时需要考虑的问题
数据密集型应用在设计时,需要考虑很多问题,例如:
- 如何保证数据的正确新和完整性,哪怕是在系统中发生错误的时候?
- 如何保证系统能够持续提供良好的性能,哪怕是在系统的部分组件已经降级的时候?
- 如何保证系统的弹性,来应对不断增长的负载压力?
本系列文章,主要讨论设计数据密集型应用时所需要满足的3个重要特性:可靠性(Reliability)、可扩展性(Scalability)以及可维护性(Maintinability)。
可靠性
当系统中出现错误的时候,仍然需要保持正常工作,否则就会影响到线上服务的稳定,给业务带来利润和声誉上的损失。
系统中每天都可能发生各种各样的错误,比如磁盘损坏、程序bug、运维出错等等。我们可以通过提高机器规格、优化程序质量、引入DevOps实践等多种方式减少错误的发生,但是完全杜绝错误的发生是不现实的。所以系统在设计时,需要考虑如何在错误发生时,也能够正常运行,这被称作系统的容错性。容错性好的系统,能够在错误发生时,表现得足够健壮,防止错误扩大引发故障。
为了验证系统的容错能力,我们甚至会在系统中人为注入错误进行演练,来帮助发现系统的脆弱点,提升系统的健壮性。
可扩展性
当数据量、数据复杂度增长的时候,系统需要找到合适的方式来应对负载的增长。扩展性用来描述系统处理更多负载的能力。
系统的扩展方式,可以分为向上扩展(垂直扩展,使用更加强大的机器)和向外扩展(水平扩展,使用更多的机器)。只在单机上运行的程序设计起来比较简单,但是高性能的机器可能会变得非常昂贵,所以当前更多地使用向外扩展的方式来部署分布式程序。在云环境中,甚至可以根据负载的变化,对机器数量进行动态的扩容和缩容。
为了能够让系统具有好的扩展性,我们需要尽量把系统设计成无状态(shared-nothing)架构,否则扩展的时候会面临很多额外的复杂性。
对于不同的负载类型,针对扩展性所作出的架构设计决策通常也不同,不存在一套通用的高扩展性架构。设计出可扩展系统的前提,是正确理解系统中的负载类型(比如负载主要是读请求还是写请求)。
可维护性
系统上线后的的维护,比如修复bug、日常运维、出错排查、迁移到新平台、偿还技术债、添加新功能等等,是软件生命周期中需要付出的主要成本。历史系统维护,可能是每个程序员都不愿去做,又不得不去面对的事情。
我们在设计系统时,应当努力降低其维护成本,遵循以下3个设计原则:
-
可运维(Operability)
遵循DevOps实践,让日常运维工作变得简单。
全链路监控系统的运行情况,统计各项运行指标,全面记录日志,在出错的时候能够迅速定位到问题点。 -
简单清晰(Simplicity)
软件的演化是一个不断熵增的过程,失控的复杂度会让软件变成一个焦油坑,让团队深陷其中。
软件架构设计的核心目标之一,就是管理演化过程中的复杂度,通过合理的抽象和分层,保证系统的复杂度控制在人们可以理解的范围之内。 -
可演化(Evolvability)
软件总是在不断的演化,新功能需要不断地被添加到已有系统中。软件架构需要足够的简单清晰,才能让新功能能易于添加,而不必总是担心引起预期外的影响。
敏捷开发的核心目标之一,就是保证系统的可演化能力。通过Scrum、TDD等手段,快速响应开发过程中的变化。
总结
为了实现数据密集型应用的目标,我们在设计的时候,既要考虑功能性需求,也要考虑非功能性需求,包括可靠性、可维护性、可扩展性。达成目标并非易事,需要我们具有全局且深入的理解,下面让我们从最基础的数据模型开始,启动数据密集型应用设计之旅吧!