引言
基于云平台的应用如雨后春笋般涌出,任务处理应用如Hadoop,Spark,Storm,服务调度应用Marathon, Aurora, Chronos, 数据库Redis, Cassandra, Mongodb, 搜索引擎ElasticSearch, 消息系统kafka。面对如此纷繁的应用,需要一个操作系统,在应用之间分配集群资源,在此背景之下,云世界的操作系统——mesos, 应运而生。
本文是Mesos的学习笔记,主要基于Mesos white paper, 和Mesos系列博客。
设计
挑战
Mesos在设计时的主要挑战如何适配任务和资源,原因在于:
- 解决方案必须支持当下和未来的框架
- 解决方案必须具有高扩展性,现代集群通常会有上万个节点,同时跑数百万个任务。
- 资源调度系统必须具有高可用性和高容错性
决策
Mesos没有使用传统的集中式调度方案(YARN),因为传统方案有以下缺陷:
- 复杂性,需要满足各种框架的资源使用需求
- 许多框架自身已经实现了资源调度策略,将这些算法融合到Mesos将付出巨大的重构成本
Mesos采用了不同的策略,将调度控制委托给框架, 基于“resource offer”的形式,由Mesos决定向每个框架提供多少资源,框架自己来决定接受哪些资源,并基于这些资源进行任务调度,这样的设计有以下好处:
- 让框架近乎完美地达到调度目标(如数据本地性)
- 简单并且易于实现
- 可以运行一个框架的不同版本
- 可以让框架更加专注于特定领域的问题
优势
通过在不同框架之间分享集群资源,不仅提高了资源利用率,也提高了数据利用率,并且让上层的框架不需要重复地实现与分布式基础架构交互的细节,从而能够专注于解决特定领域的问题。
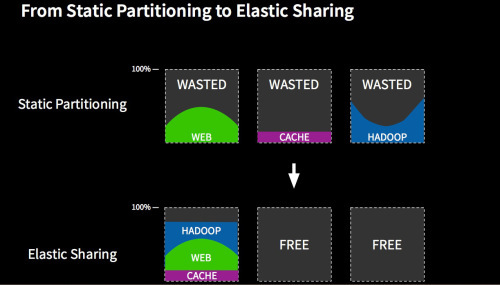
下图为基于传统的静态划分和基于Mesos的弹性分享之间的资源利用率对比:
架构
Mesos 架构如图:
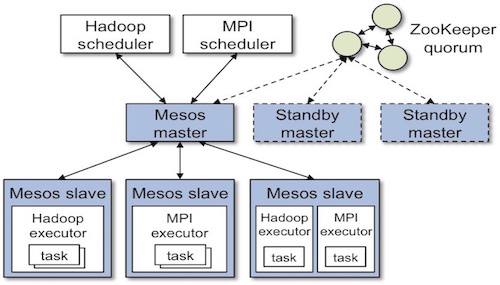
Mesos 由一个master进程和一组slave进程组成。
-
Master负责为不同的框架提供资源,并且管理task的生命周期。
-
Slave负责启动框架定义的executor并执行相应的任务。
-
运行在mesos之上的框架(也称为应用)包含两个组件:
- 负责资源调度的调度器(scheduler)
- 负责任务执行的执行器(executor), 每一个executor可以通过多线程的方式运行多个task,也可以只运行单个任务。
实现
Mesos由10000行C代码实现(最新的v0.24共计176545行C代码,master.cpp 和 slave.cpp 合计约10000行),可以在Linux, Solaris 和 Mac OSX 上运行,通过SWIG支持Python 和 Java API.
使用c++库libprocess实现基于actor模式的异步I/O 机制(epoll, kqueue之类), 已经在twitter, facebook的实际生产环境中使用.
资源调度
Master基于"resource offer"实现了细粒度的资源调度方式,下图是一个"resource offer"示例:
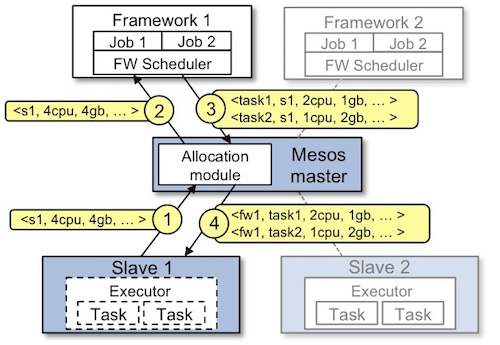
- slave1 向master报告,它拥有4cpu 和4GB内存的空闲资源
- master向framework1发送一份“resource offer”, 描述当前所有的空闲资源
- framework 的调度器回复需要运行两个task, task1 需要<2CPU, 1GM RAM>, task2 需要<1CPU, 2GM RAM>
- master 把task发送给slave,slave为执行器分配资源,执行器启动这两个任务。
- 由于仍有1CPU 和 1GB RAM剩余,master可以把它们提供给framework2.
在和框架进行通信时,Mesos Master以JSON格式发送"resource offer", 例如:
1 | { |
资源分配算法
resource offer 的决策由master的资源配置(resource allocation)模块作出, 保证在多个框架之间分享资源的公平性。
Max-min
在一个同质化的环境中(如仅运行Hadoop的集群),最著名的分配算法是max-min算法,该算法通过在users之间均分最紧缺资源的方式,保证集群中最紧缺的资源得到最大化利用。
DFS
但是在一个异质化环境中,不同的框架拥有不同类型的紧缺资源, max-min算法将不再适用。 比如框架A每个task需要1CPU, 4RAM,框架B需要3CPU, 1RAM, 如何给这两个框架分配资源才算公平呢?
Mesos使用了DFS(Dominant Resource Fairness)算法, 目标是实现支配性资源的公平分配。
支配性资源,是指框架在运行时的瓶颈资源,比如一个计算密集型的框架,CPU就是其支配性资源。
看一个具体的例子,假设集群中现有的资源为9CPU 和 18GB RAM, 框架A每个task需要1 CPU, 4 GB RAM, 框架B每个task需要3 CPUs, 1 GB RAM。对于框架A来说,每个task需要总资源的1/9CPU和2/9RAM,其支配性资源是RAM,对于框架B来说,每个task需要总资源的1/3 CPU和1/18 RAM,其支配性资源是CPU。
DRF作出的最终资源分配决策为:为框架A分配3个task的资源 (3 CPUs, 12 GB RAM), 为框架B分配两个task的资源 (6 CPUs, 2 GB RAM). 最终两个框架支配性资源的份额相同(均为67%), 并且集群中不再有额外资源分配给更多的task。

除了默认的DRF算法外,Mesos也提供了基于严格优先级(strict priority)的资源分配算法, 具有高优先级的框架会被优先提供资源, 以保证集群中重要的框架总能够拥有所需资源。
一个潜在的问题是,mesos如何能满足框架对资源的特殊要求呢?比如某个框架有数据本地性的需求(data locality),但是Mesos本身并不知道哪个节点存储着框架需要的数据。
为了解决这个问题,Mesos给框架提供了"reject offer"的能力:框架可以拒绝那些不满足其特殊需求的"resource offer",而只接受那些能够满足需求的"resource offer"。
资源预留
一些重要的服务,不希望在重启的过程中被回收资源,Mesos提供了资源保留(resource reservation)的机制, 框架在接受resource offer的时候,可以告诉Mesos Master 希望保留的资源。
资源隔离
资源隔离:利用操作系统提供的隔离机制进行资源隔离,比传统的基于进程来隔离任务优越得多。
Mesos提供了三种类型的资源隔离:
- Mesos containerizer. 基于Linux cgroups 实现。
- Docker containerizer. 底层基于cgroup, LXC, OpenVZ 以及Kernel namespaces 实现。
- External containerizer, 由用户自定义实现。
容错
Master
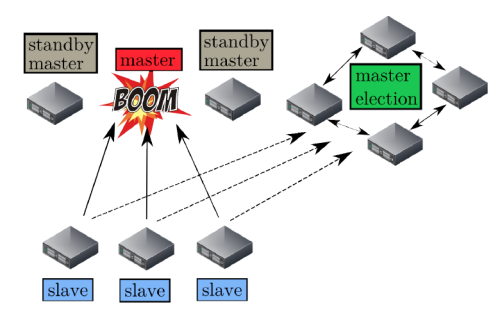
由于所以的框架都依赖master,所以master容错非常重要,mesos采用了两种技术:
- master本身被设计成轻状态(soft state), master可以根据slave及框架调度器周期性传来的信息,完整地重建先前的内部状态。
- master不是单个节点,而是一个集群,由Zookeeper来实现领导者选举,决定哪个节点作为当前master。其它的节点作为备份,在当前master挂掉之后,参与新一轮的master 选举。
框架调度器(Framework Schedulers)
框架可以向mesos master注册两个或多个调度器,来实现调度器的容错。
Slave
Slave 进程在执行的过程中,周期性地为任务相关的元数据生成还原点(checkpooint), 并存储到本地磁盘。如果slave挂掉,master会重启slave进程,并且根据还原点数据重建先前状态。
在slave挂掉的这段时间,task可以不受影响地继续执行,slave 进程被重启后可以重新连接到executors/tasks.
总结
Mesos遵循了UNIX设计哲学,专注于提供核心功能–资源分配,而将其它功能诸如任务调度代理给上层应用完成。
Mesos最重要的两点设计:
- 实现了task级别的细粒度资源共享模型。
- 实现了称作"resource offer"的分布式资源调度模型,由Mesos提供集群资源,框架来选择使用哪些资源运行任务。