Spark 核心
Spark是继Hadoop之后的下一代分布式大数据处理框架,相对于传统的批处理框架Hadoop,Spark通过可存储在内存中的数据集RDD,以及对流式(streaming)处理的支持,可以获得10到100倍的性能提升。相对于仅支持流式处理的Storm框架,Spark提供了对批处理,流处理,交互式查询,机器学习及图形计算等一系列任务的支持,一站式解决各类大数据分析需求。
每个分布式框架需要解决分布式环境中天然的技术难题,比如并行效率,出错恢复和一致性等问题。分布式框架本身需要精巧的设计,但是对使用框架的用户来说,需要实现的客户端代码是比较简单直接的,无非是对数据集合的map, reduce, filter, group, join等一系列操作。
然而要实现高效的Spark应用,需要用户对数据在物理节点上的存取,在网络间的传递,以及任务的执行流程有清晰的理解,RDD和DAG是需要掌握的两个核心概念。
RDD
概念
RDD(resilient distributed datasets, 弹性数据集),是一组分布存储于多个数据节点,可执行并行操作的数据集合。RDD是Spark的核心抽象,其主要特点为:
-
不可变性(immutable)
RDD一旦生成,其内容是不可变的,只会基于已有的RDD生成新的RDD。不可变性是函数编程给分布式世界带来的最宝贵财富,是征服分布式环境中的并发,容错等问题的利器。
-
分布式(distributed)
集合是函数式编程中的主要数据结构,Spark将其推广到了分布式环境,利用现有的分布式数据存储框架(HDFS, S3)等,将数据存储于集群的多个节点,方便了任务并行和数据容错。
-
并行(parallel exection)
基于特定的分区函数,Spark将RDD存储到多个分区(Partition), 实际任务执行时,为每个分区起一个线程并执行相应的计算逻辑,通过并行提高了任务执行的效率。
程序示例
Spark应用中主要做的事情就是将一个RDD变换成另一个RDD,举一个实际的代码示例:
1 |
|
如果在spark-shell里执行val input = sc.textFile("README.md"), 可以看到input的类型为org.apache.spark.rdd.RDD[String], 事实上input, words 及 counts这些由transformation操作生成的对象,都是RDD类型,基于RDD,Spark提供了一系列机制来加速任务的执行。
加速原理
tranformation 和 action
transformation 的输入是RDD,输出也是RDD。action的输入是RDD,输出是一个值,通常是在Spark程序的末尾被调用,得到一个计算结果。
transformation和action最大的区别在于,transformation 遵循缓式计算(lazy evaluation), 程序内部执行tranformation调用之后,并不立即进行计算,直到某个action被调用,才会进行真正的计算。结合下文提到的DAG,优化了程序的执行效率。
Spark中大部分API提供的都是transformation操作,如代码示例中的map, filter 及 flatmap, 少数API提供action操作,如count 和 reduce。
缓存(cache)
每一次action调用,Spark都会从最初的输入RDD开始,重新执行一遍所有的tranformation, 对于批处理任务,这样做固然没有问题,但是对于反复操作操作同一数据的交互式(interactive)任务, 重复执行相同的计算显得很低效。
Spark提供缓存API来解决这一问题,用户可以通过cache()或persist()方法,将中间计算结果缓存到内存或者硬盘,下次执行相同计算时,可直接读取缓存来提高效率。persist()和cache()的区别在于,persist()提供了更多的参数,来支持不同级别的缓存机制。
分区(partition)
Spark按照分区函数(通常是哈希函数),将RDD数据集切分成多个分区,分布到多个物理节点。
Spark 提供了一系列的API,以分区为基本物理单元进行数据存取和计算。一些昂贵的操作比如创建数据库连接,为每个分区建立一个显然比为每个数据对象建立连接一个高效得多。
灾备原理
分布式环境中,节点失效是常态,数据备份和出错恢复是每一个分布式框架必须处理的问题。基于RDD,Spark 对数据灾备提供了一系列支持:
血统(lineage)
每个RDD都是由最初的输入RDD,经过一系列tranformation生成的,Spark记录了这一系列transformation构成的变换图谱,称之为RDD的lineage。用户可以调用RDD的toDebugString()方法打印出lineage。如果缓存的RDD发生了数据丢失,Spark可以根据lineage,重新计算出该RDD。
副本(replica)
当然原始输入数据也可能发生丢失,Spark依赖副本来处理这种情况。很多存储系统如HDFS 或 S3, 本身就存储了副本,而对于诸如并未提供副本机制的本地文件系统,可以在应用程序中让Spark帮助我们存储备份。
DAG
RDD是对计算对象的抽象,DAG是对计算过程的抽象。DAG(directed acyclic graph, 有向无环图), 描述了任务执行的拓扑结构,代表了从输入RDD到结果RDD的变换关系。
narrow transformation 与 wide transformation
Spark 将那些需要在节点间传输数据的tranformation 称为 wide transformation, 如 reduceByKey, join 这类 shuffle 操作。 相应的,可以在单一节点完成的操作称之为 narrow transformation, 如 map 和 filter, Spark 可以针对narrow transformation做优化,将一组narrow transformation合并执行。
job, stage 与 task
按计算步骤的粒度,Saprk提供了job, stage 和 task 三层概念抽象:
-
task - Spark中最小的任务执行单元,每个
tranformation操作,都会被翻译成相应的task,由executor应用到相应的RDD上。 -
stage - 一组由
narrow transformation构成的task,被合并成一个stage,由于不需要在节点间传输数据,stage可以被高效执行。 -
job - 每一个
action在实际执行时,对应着一个job,一个job可以包含多个stage。
程序示例
上文中的单词计数程序,对应的DAG为:
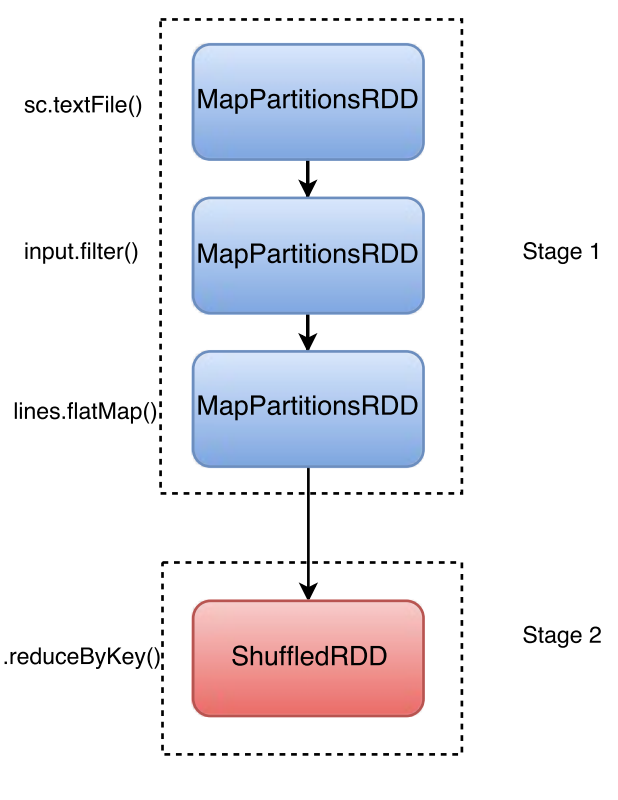
用户也可以通过 Saprk Web Interface 获得类似的DAG视图。
小结
相对于上一代分布式计算框架Hadoop,Spark基于RDD和DAG,对分布式任务处理提供了更加高效和灵活的支持。深入掌握RDD和DAG的原理,可以为理解整个Spark框架奠定坚实的基础。