初识Akka
并发,是计算机世界与生俱来的命题,从CPU的分时处理,到web网站响应多用户请求,无处不彰显着并发的力量。
概言之,并发模型可分为两种,共享可变状态模型和消息传递模型。
多线程是共享可变状态模型的经典例子,上一篇我们已经简要解释了这种模型的问题。
消息传递模型有两种经典的实现,一种是CSP(Communicating Sequential Processes), 例如Golang中的Goroutine和Channel, 另一种是Actor, 例如Erlang的OTP和Scala的Akka。相对于CSP,Actor更加适应分布式环境。
核心概念
在Akka中,Actor和Future两大核心概念。
Actor最经典的应用是Erlang, 在Erlang中,Actor对应轻量级进程,在Akka中,Actor对应着JVM中的轻量级对象。传统线程的创建和切换需要消耗大量的内存和机器周期,而Akka可以轻易并发数百万Actor。
Future源自函数式编程,使我们可以方便地实现异步API。异步API典型的例子是NodeJS, 所有的调用都是异步调用,调用者立即返回,被调用函数在完成之后执行回调函数。异步API在处理大量的并发请求时,比同步API更加优雅和高效。
Akka之道
上一篇我们提到,传统的并发编程之所以困难,是因为我们使用了错误的工具在错误的层面进行了错误的抽象。
传统并发模型错误的根源在于共享可变状态,Akka如何解决这个问题呢?
Akka由Scala实现,继承了函数式编程的基因。在函数式编程的世界里,不存在可变量,要获得一个新的值,就需要创建一个新的对象。在纯粹的函数式编程语言如Haskell中,需要用Monad这样的复杂机制来支持副作用。
Scala折衷了函数式编程和面向对象编程,在Akka中,可变量(var)并没有被完全禁绝,但是被严密地封装在Actor内部:
- 要改变Actor的状态, 只能给Actor发送消息,由Actor内部定义的消息处理逻辑来更新状态。
- Actor之间,只能通过消息进行通信,消息本身是不可变量。
总而言之,在Actor内部,允许存在不可变量,但是不会被共享。在Actor之间,会共享消息,但是不会传递可变量。既避免了传统并发的陷阱,又方便了业务逻辑的实现。
并发 —— 于Actor之内
在Actor内部,如何同时处理多条消息呢?
答案是做不到,Actor从不同时处理多条消息,每个Actor逻辑上单线程地一条条处理发送给它的消息,Actor内部实现的是并发而非并行。(参考并发与并行的区别)
每个Actor内部,都有一个用于接收和处理消息的邮箱(mailbox)和分发器(dispatcher):
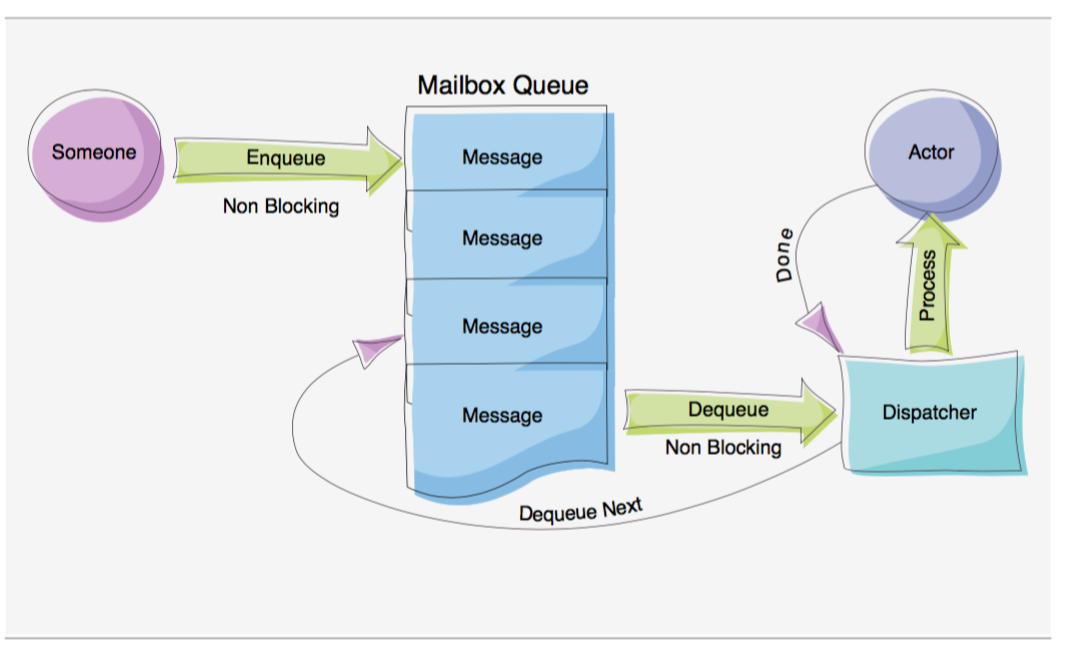
- 每次Actor接收到外部消息时,会将它插入mailbox的头部。
- dispatcher会被唤醒,如果Actor空闲,则新消息会被分发给Actor进行处理,否则dispatcher什么也不做。
- 每当Actor处理完一条消息,会唤醒dispatcher,如果mailbox此刻非空,dispatcher会分配新的消息给Actor处理。
- 虽然每条消息可能会在不同的物理线程被处理,但是任何时刻Actor内部不会有两条消息被同时处理,Actor的消息处理机制在逻辑上是单线程的。
并行 —— 于Actor之外
既然Actor以单线程的方式处理消息,岂不是要像Python, Ruby那样,无法利用现代计算机的多核来提高性能?
实则不然,Akka程序中,一切皆Actor,会有许多的Actor被创建来负责不同的任务,这些Actor之间彼此独立,可以在不同的线程中并行运行,底层运用的是JVM的fork-join模型。(参考fork-join与thread pool 的区别)
性能保证
整个Akka框架采用反应式编程(Reactive Programming)模型,遵循事件驱动(Event Driven)机制,每个Actor对接收到的消息作出响应。
Actor并不独占一个线程,那样设计需要非常昂贵的线程开销,并限制整个系统的并发量。每当Actor处理消息时,会将该消息放到一个空闲的线程中处理,保证了线程使用效率并提高了系统整体的并发性。
以上是对普通消息的处理,再来看两种极端的例子:
- 消息处理逻辑中涉及阻塞IO或者耗时运算。这种情况下,我们可以用Future引入异步处理,让Actor不必阻塞于这条消息,可以继续处理后续消息。
1 | val futureResult = Future { expensive_calculation() } |
- 数据库连接(DB Connnection)。建立数据库连接是昂贵的操作,我们不能够为每一条SQL查询新建一个数据库连接。可行的做法是利用Akka的Rounter机制,由一组Actor维护一个数据库连接池,并由一个Router Actor来调度查询请求。
容错(fault-tolerant)
分布式系统中,出错是常态,容错至关重要。
传统程序中使用异常处理来解决错误,但异常处理有其固有的缺陷,人们总是寄希望于系统抛出异常的时候,能够根据异常的类型采取相应的策略恢复系统运行行。但是现实情况是,异常发生的时候,我们能做的事情并不多,通常是写条日志然后退出。在分布式世界中,由于环境更加复杂,容错面临更加严峻的挑战。
Let it crash
目前分布式系统的容错机制,大多借鉴了Erlang “let it crash”的思想,比如Hadoop中的冗余备份(replication), Spark 中的Checkpoint和Linage。“let it crash”的核心理念是,出错是常态,我们不要去试图修复,而是创建一个新的组件。
如果你的车坏了,通常的想法是会去4S店维修,但是有可能修好,也有可能修不好,有也可能修好了却引发别的部件故障。土豪的做法是 —— 换辆新的。Akka的世界里,我们每个人都是土豪。
Error Kernel Pattern
整个Akka系统,被设计成一个树形结构,底层的子Actor由其上一层的父Actor创建并管理。

Error kernel pattern的同样来源于Erlang,其核心思想在于,处于上层的Actor承担风险较小的任务,处于底层的Actor承担更加危险的任务,出错之后就"let it crash"。
可扩展(scalable)
并行能力,描述的系统的纵向扩展性,即在一个节点内部,可以同时执行任务的数量。
分布式系统一个重要指标是横向扩展性,即同时在多个节点执行任务的能力。Akka利用Actor Path来实现透明扩展。每个Actor,无论是本地还是远程,都由唯一的地址进行标识。
本地Actor地址示例:
1 | akka://RedPacket/user/redPacketGenerator |
远程Actor地址示例:
1 | akka://RedPacket@{host}:{port}/user/redPacketGenerator |
一个Acotr处于本地还是远程,对应用程序是透明的,Akka可以很容易在不同的节点上面创建Actor,实现了整体的高扩展性。
出发
Akka的原理就介绍到这里,后续会详细介绍Akka的每个模块,并给出详细的代码示例,get your hands dirty!